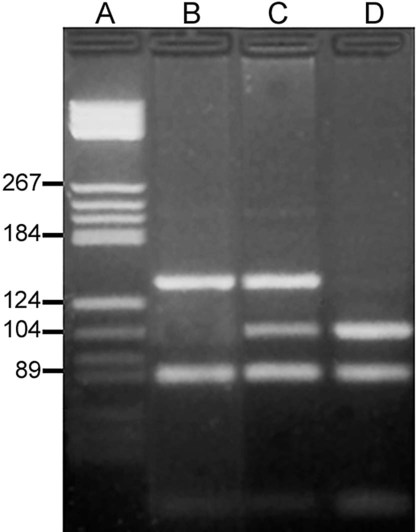
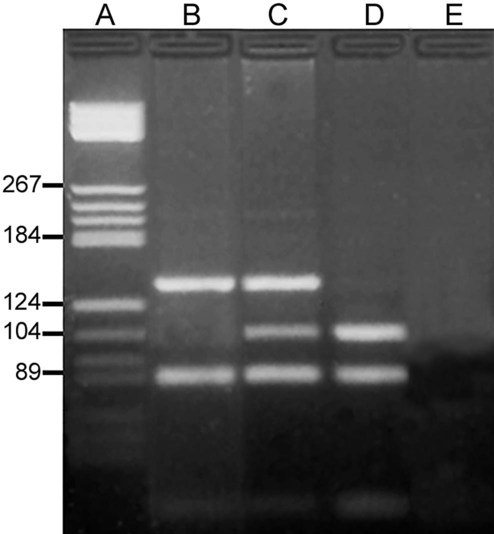
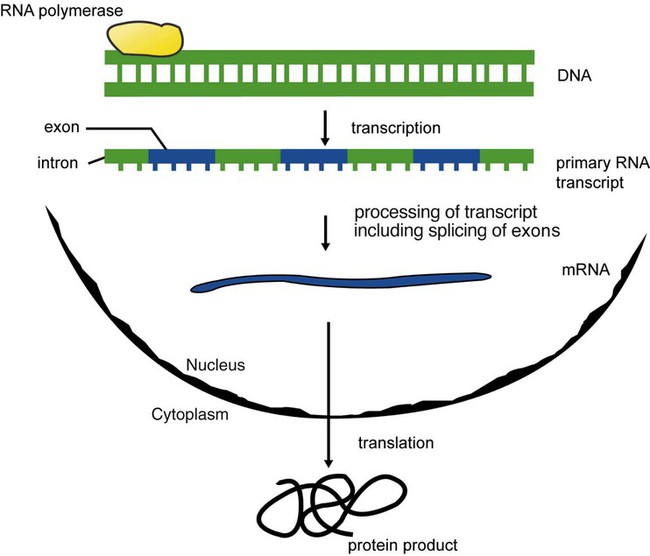
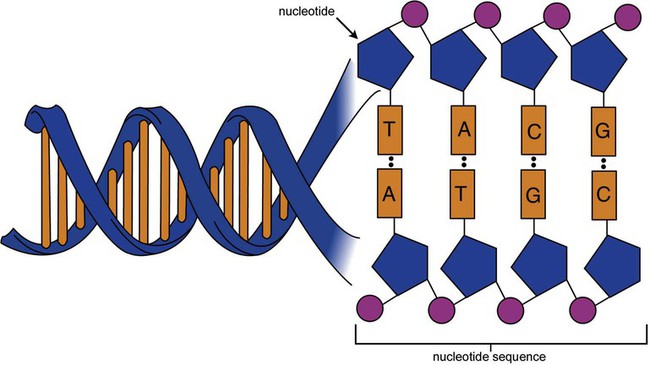
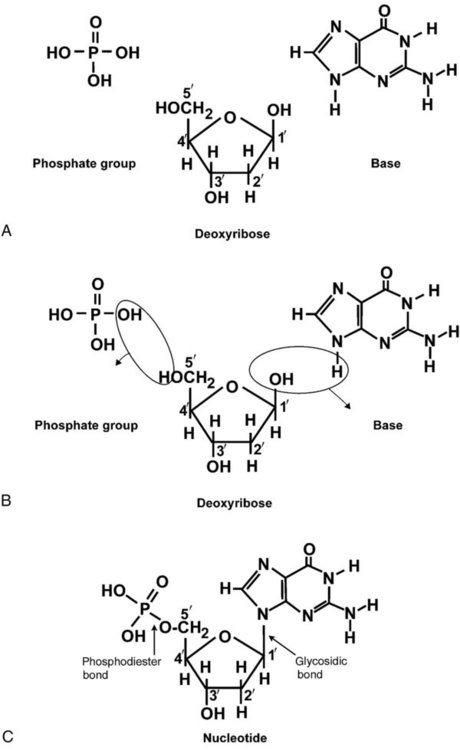
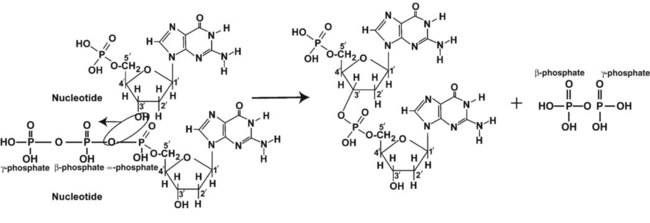
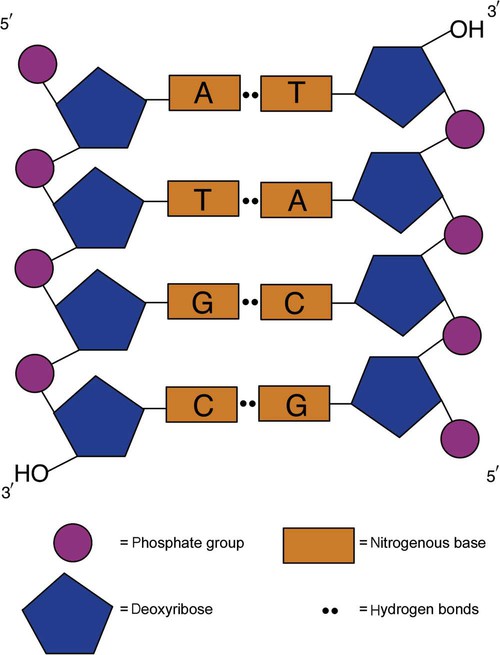
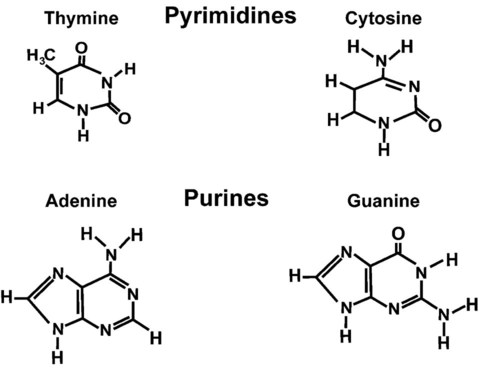
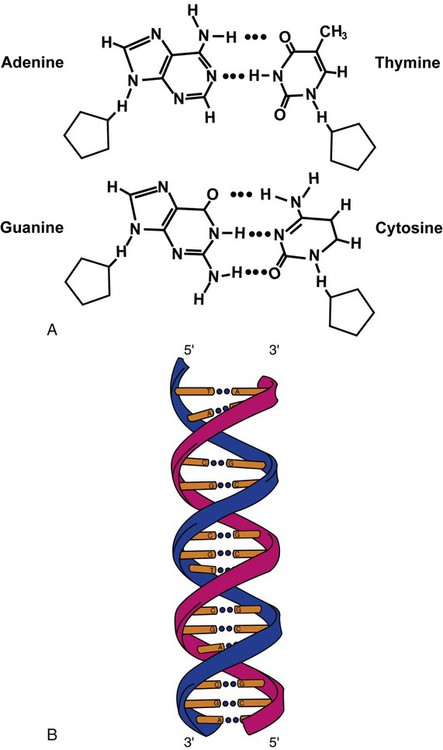
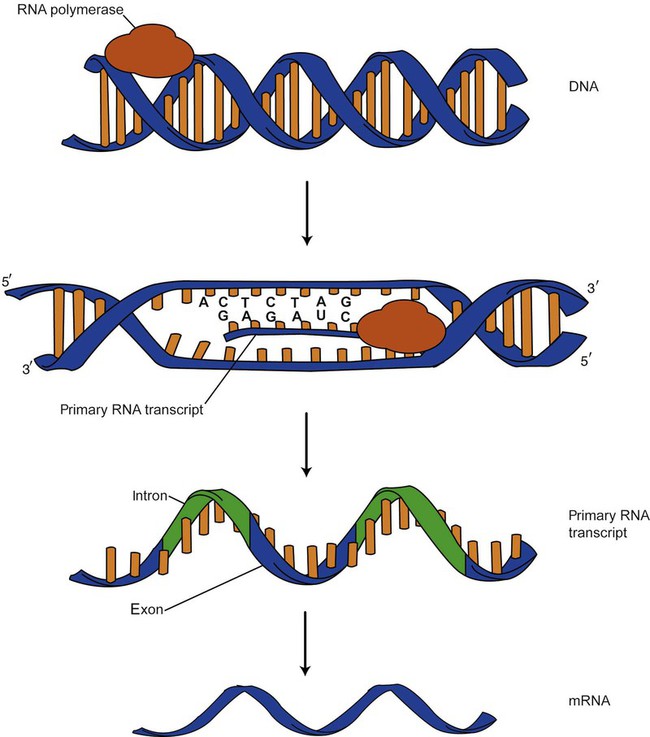
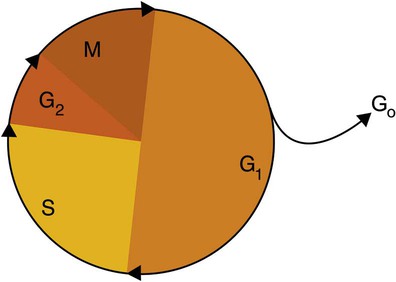
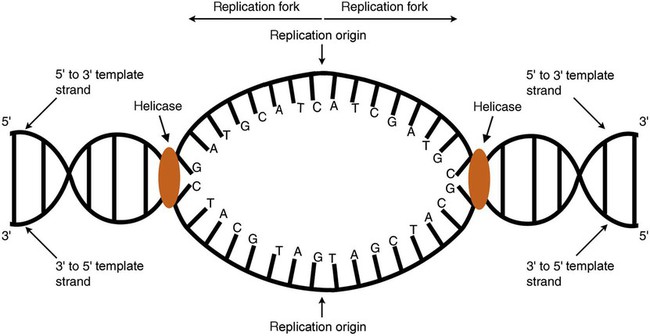
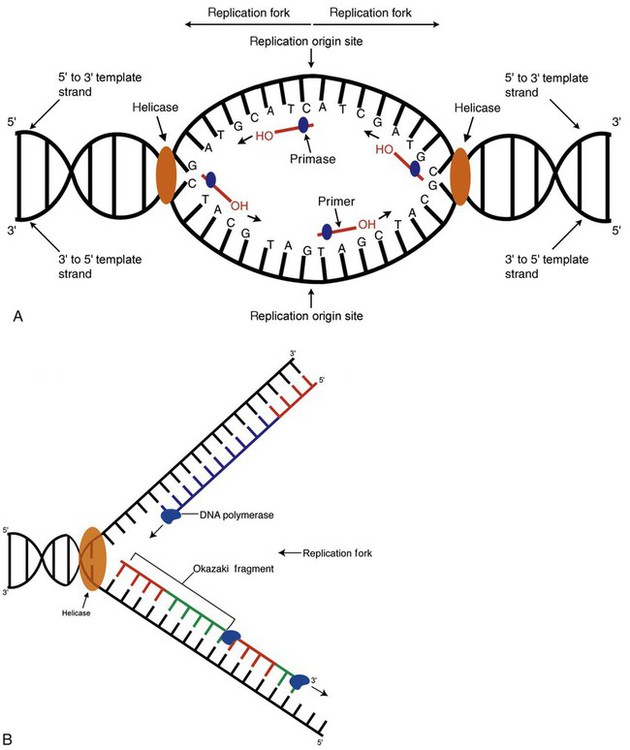
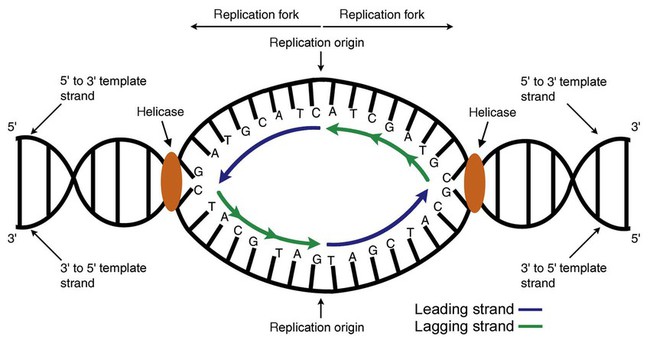
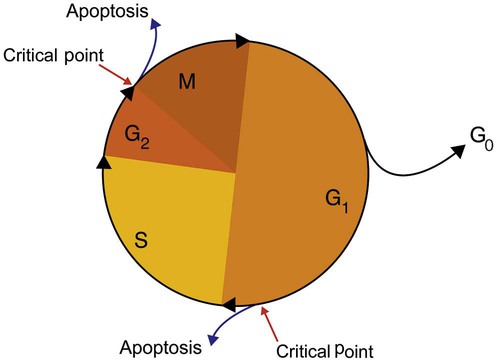
After completion of this chapter, the reader will be able to: 1. Describe the structure of DNA, including the composition of a nucleotide, the double helix, strand orientation, and the antiparallel complementary characteristic. 2. Predict the nucleotide sequence of a complementary strand of DNA or RNA given the nucleotide sequence of a DNA template. 3. Explain the relationship between DNA structure and protein production. 4. Explain the relationship between the cell cycle and tumor progression. 5. Discuss the process of DNA replication, including replication origin, replication fork, primase, primer, DNA polymerase, Okazaki fragments, leading strand, and lagging strand. 6. Determine the appropriate patient specimen required for DNA isolation to identify an inherited or somatic mutation. 8. Explain the purpose of polymerase chain reaction (PCR), reverse transcription PCR, and nucleic acid hybridization. 10. Compare and contrast the methods for detecting amplified target DNA: (1) gel electrophoresis using either ethidium bromide or autoradiography, (2) restriction fragment length polymorphism, and (3) probe hybridization techniques such as Southern blotting. 11. Interpret an agarose gel electrophoresis result for the factor V Leiden mutation test and a nucleic acid hybridization result for a B- and T-cell gene rearrangement test. 12. Describe the principle of real-time quantitative PCR. 13. Discuss the use of real-time PCR for monitoring minimal residual disease. After studying this chapter, the reader should be able to respond to the following case study: On physical examination, the patient had no evidence of rash or oral ulcers. No petechiae or purpura were noted. He had mild pretibial pitting edema. His right leg measured 36.5 cm at 25 cm distal to the superior aspect of the patella, whereas his left leg measured 33.5 cm in the same location. CBC findings were unremarkable, and both the prothrombin time and activated partial prothrombin time were within the reference ranges. Doppler ultrasonography revealed complete occlusion of the distal superficial femoral vein, anterior tibial vein, and popliteal vein. The diagnosis was DVT without pulmonary emboli. The patient was hospitalized, and a heparin drip was started. The hematologist ordered a factor V Leiden analysis. The initial specimen received was drawn into a red-topped tube. The laboratory scientist requested a redraw using a lavender-topped tube. The patient was still hospitalized, which allowed the collection of a blood specimen in an EDTA tube. Figure 32-1 illustrates the results of the factor V Leiden mutation test initially done by the molecular scientist. The scientist’s supervisor reviewed the gel electrophoresis results and requested that the scientist repeat the analysis. Figure 32-2 represents the repeated analysis. 1. What type of specimen is appropriate when analyzing DNA for a hereditary mutation? 2. Examine the first gel electrophoresis result (see Figure 32-1). Are the correct controls present? 3. Examine the second gel electrophoresis result (see Figure 32-2). What band sizes appear in the patient’s sample? 4. What band sizes are expected for an individual who is homozygous for the factor V Leiden mutation, heterozygous for the mutation, and free of the mutation? 5. Why did the laboratory request that the blood sample to be redrawn? 6. Why was a repeat analysis requested? Molecular biology techniques enhance the diagnostic team’s ability to predict or identify an increasing number of diseases in the clinical laboratory. Molecular techniques also enable clinicians to monitor disease progression during treatment and to make accurate prognoses. The short interval required to perform molecular diagnostic tests and analyze their results is an additional positive aspect of this type of testing, resulting in more efficient patient management, especially in cases of infection. The three main areas of hematopathologic molecular testing include detection of chromosomal translocations in hematologic malignancies (Box 32-1) and inherited hematologic disorders (Box 32-2), identification of hematologically important infectious diseases (Box 32-3), and monitoring of minimal residual disease after cancer treatment. The central dogma in genetics is that information stored in the DNA is replicated to daughter DNA, transcribed to messenger ribonucleic acid (mRNA), and translated into a functional protein (Figure 32-3). This process is essential to carry out cellular functions while preserving a record of the stored information. In eukaryotes, the initial DNA sequence is composed of exons separated by untranslated introns. The introns are enzymatically excised during transcription from DNA to RNA, and the mature mRNA sequence is then translated. Translation is an enzymatic process wherein mRNA three-member base sequences called codons drive the addition of individual amino acids to the growing peptide. The mature protein then carries out its cellular function, which may be structural or may involve recognition, regulation, or enzymatic activity. The structural units that carry DNA’s message are called genes. The human β-globin gene, part of the hemoglobin molecule, provides a good example of replication and transcription, because it was one of the first sequenced and demonstrates the result of aberrant sequence maintenance. A normal (or wild-type) β-globin gene contains a sequence of bases that code for a β-globin peptide of 146 amino acids. One inherited mutation changes a single DNA base. This is called a point mutation. The mutation occurs in the portion of the sequence that codes for the sixth amino acid of β-globin. The mutation substitutes the amino acid valine for glutamine in the growing peptide. Valine modifies the overall charge, producing a protein that polymerizes in a low-oxygen environment. This leads to sickled erythrocytes, circulatory ischemia, and poor oxygen exchange between blood and tissues.1,2 A mutation in one of the two copies (alleles) of this gene inherited from the parents results in a heterozygous condition, or a sickle cell trait. In a heterozygote, the symptoms of the disease are often unseen or are present only during times of physical stress. If both alleles are mutated, there is overt homozygous sickle cell disease, and the symptoms are severe. Every active gene is translated. Human somatic cells contain 20,000 to 25,000 genes in 2 meters of DNA.3,4 Significant packing (see Chapter 31) takes place to reduce the volume of the nucleic acid to the size of chromosomes. DNA is a duplex molecule composed of two complementary hydrogen-bonded nucleotide strands (Figure 32-4). Deoxyribonucleotides and ribonucleotides are the building blocks of DNA and RNA, respectively. Each nucleotide is composed of a 5-carbon sugar (pentose), a nitrogenous base, and a phosphate group (Figure 32-5). The numbers one prime (1′) to five prime (5′) designate the pentose’s carbons. In DNA, the pentose is a ribose in which the hydroxyl group on the 2′ carbon is replaced by a hydrogen molecule, hence 2′-deoxyribose. In RNA, the 2′ ribose retains the 2′ hydroxyl group. The hydroxyl group present on the 3′ carbon of the sugar is crucial for polymerization of the nucleotide monomers to form the nucleic acid strand. Creation of a phosphodiester bond between the 3′ hydroxyl group of the existing strand and the 5′ α-phosphate of the nucleotide monomer requires the protein enzyme DNA polymerase. This enzyme recognizes the hydroxyl group on the 3′ carbon of the sugar and bonds the 3′ hydroxyl group of one nucleotide with the α-phosphate group of another (Figure 32-6). Polymerization of subsequent nucleotides forms a DNA strand. DNA consists of two strands that are antiparallel and complementary (Figure 32-7). One strand begins with a phosphate group attached to the 5′ carbon of the first nucleotide oriented to the left and ends with the hydroxyl group on the 3′ carbon of the last nucleotide oriented to the right. This strand is in the 5′-to-3′ direction. The other strand runs in the 3′-to-5′ direction, or antiparallel. The nucleotide sequences composing these strands provide the encoded messages of our genes. Therefore, the addition of nucleotides is highly regulated. One regulation mechanism arises from the complementary characteristic of the nucleotides. A nucleotide’s identity depends on the type of nitrogenous base present on the template. There are two categories of nitrogenous bases in nucleic acids, purines and pyrimidines (Figure 32-8). The bases adenine (A) and guanine (G) are double-ringed purines, whereas thymine (T) and cytosine (C) are single-ringed pyrimidines. Adenine forms hydrogen bonds at two points with thymine (A:T), whereas guanine forms hydrogen bonds at three points with cytosine (G:C). If a strand has a 5′-CTAG-3′ sequence, the complementary nucleotides on the 3′-to-5′ strand are 3′-GATC-5′. In RNA, the pyrimidine uracil (U) takes the place of thymine and forms hydrogen bonds with adenine. Hydrogen bonds between A:T and G:C hold the strands together (Figure 32-9). RNA is most often single-stranded. DNA provides a permanent set of instructions. The cellular enzyme RNA polymerase transcribes the code. RNA polymerase recognizes starter sequences called promoters. Promoters lie upstream of coding sequences and bind RNA polymerase to separating DNA strands. The enzyme then slides along the DNA strand 3′ to 5′, “reading” the code and polymerizing (assembling) the complementary ribonucleotides. As the complementary ribonucleotides form hydrogen bonds with the bases of the exposed DNA strand, the RNA polymerase creates phosphodiester bonds to extend the single-stranded primary RNA transcript (Figure 32-10). If the nucleotide sequence of the DNA strand is 3′-CTAG-5′, the primary RNA transcript is 5′-GAUC-3′. Primary mRNA segments are composed of introns and exons. Introns are untranslated intervening sequences located within the coding portions of genes. Their functions remain unclear, although they may play a role in regulation of gene expression.5 Exons are the sequences that encode the gene product. Before mRNA can serve as a translation template, the introns must be excised from the primary transcript and the exons adjoined. The mature mRNA is completed by the addition of a 5′ cap and a tail of many repeated adenine nucleotides.6 The mRNA leaves the nucleus and enters cytoplasmic ribosomes to be translated. After cells carry out their functions, they either divide via mitosis or die via apoptosis, also called programmed cell death. The cell cycle progresses through a sequence (Figure 32-11). Interphase is made up of the G1, S, and G2 phases. During the G1 phase, the cell grows rapidly and performs its cellular functions. S phase is the synthesis stage, in which DNA is replicated. The G2 phase is the period when the cell produces materials essential for cell division. The M phase refers to mitosis, during which two identical daughter cells are produced, each of which receives one entire set of the DNA that was replicated during S phase. Some cells exit the cell cycle during the G1 phase and enter a phase called G0. Cells in G0 normally do not reenter the cell cycle and remain alive performing their function until apoptosis occurs. DNA replication during the S phase requires a complex orchestration of events; this discussion focuses on those events that are exploited for molecular diagnostic testing. Contained within the double-stranded DNA helix are multiple origins of replication. At each origin, the enzyme helicase disrupts and untwists the hydrogen bonds, separating the DNA strands and producing two replication forks. Here a deoxyribonucleotide (deoxynucleotide triphosphate, or dNTP) polymerizes to form new complementary strands (Figure 32-12). DNA replication occurs bidirectionally from the two replication origin sites. Each DNA strand in the replication fork serves as a template for the formation of a daughter or complementary strand through the activity of DNA polymerase.7 The DNA polymerase substrate is the free hydroxyl group located on the 3′ carbon of a deoxyribonucleotide. DNA polymerase recognizes the group and catalyzes the joining of the complementary deoxyribonucleotide. DNA is read 3′ to 5′ by DNA polymerase, and the complementary strand is synthesized 5′ to 3′. A primer provides the free 3′ hydroxyl group required for DNA polymerase activity. Primers are short nucleotide polymers complementary to the template. The hybridization of the primer to the template requires the enzyme primase. At the replication origin, primase joins a primer to the 3′ end of the 5′-to-3′ (top) template strand (Figure 32-13). Then DNA polymerase recognizes the free hydroxyl group on the 3′ carbon of the last nucleotide in the primer and catalyzes the formation of phosphodiester bonds between the correct complementary nucleotide triphosphate and the primer, releasing the β- and γ-phosphate groups. DNA polymerase continues adding deoxyribonucleotides along the replication fork, going to the left of the replication origin, producing the complementary strand called the leading strand. DNA polymerase not only joins nucleotides, it also degrades the RNA primers and fills in the correct complementary deoxyribonucleotides. Because the replication of the lagging strand produces many small fragments, it is called discontinuous replication, and the fragments are called Okazaki fragments. Finally, the enzyme ligase joins the discontinuous fragments. The replication fork to the right (downstream) is replicated in the same fashion, although the lagging strand is now formed complementary to the top (5′-to-3′) strand, and the leading strand is formed from the 3′-to-5′ strand; the opposite of the situation described occurs for the left replication fork (Figure 32-14). The cell cycle is highly regulated. At certain critical points within the cycle, decisions are made to continue or begin cell death via apoptosis. This decision may depend on the state of the DNA replicated (Figure 32-15). Normally, the cell detects errors made during replication and either corrects them or begins apoptosis. This prevents the persistence of daughter cells with genetic errors. If the sensing molecules fail, cell division may continue. Debilitating mutations that mediate cell cycle control may result in tumor formation. One protein responsible for signaling damaged DNA is p53, a tumor suppressor protein. Damaged cells with increased p53 arrest cell division at G1, which allows time for DNA repair (Figure 32-16). Cells with mutant p53 are unable to arrest cells in G1; they continue the process of cell division with damaged DNA.8–10 If the cell can repair the DNA damage, the cell cycle continues. If the cell damage is too severe, the cell undergoes apoptosis. Hematologic malignancies, such as 21% of chronic myelogenous leukemias (CML),11–13 23% of chronic lymphocytic leukemias (CLL),14–16 and 17% of acute lymphoblastic leukemias (ALL),17–19 are associated with a p53 mutation or deletion (see Box 32-3). In summary, DNA synthesis and accurate cell cycle control demand that the integrity of the nucleotide sequence be maintained during DNA replication.
Molecular Diagnostics in the Clinical Laboratory
Case Study*
Structure and Function of Dna
The Central Dogma: DNA to RNA to Protein
DNA at the Molecular Level
Transcription and Translation
DNA Replication and the Cell Cycle
![]()
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


Molecular Diagnostics in the Clinical Laboratory