Antibody Structure and Function
Introduction
One of the major functions of the immune system is the production of soluble proteins that circulate freely and exhibit properties that contribute specifically to immunity and protection against foreign material. These soluble proteins are the antibodies, which belong to the class of proteins called globulins because of their globular structure. Initially, owing to their migratory properties in an electrophoretic field, they were called γ-globulins (in relation to the more rapidly migrating albumin, α-globulin, and β-globulin); today they are known collectively as immunoglobulins (Igs).
Immunoglobulins can be membrane-bound or secreted. Membrane-bound antibody is present on the surface of B cells where it serves as the antigen-specific receptor. The membrane-bound form of antibody is associated with a heterodimer called Igα/Igβ to form the B-cell receptor (BCR). As will be discussed in Chapter 8, the Igα/Igβ heterodimer mediates the intracellular signaling mechanisms associated with B-cell activation. Secreted antibodies are produced by plasma cells—the terminally differentiated B cells that serve as antibody factories that reside largely within the bone marrow.
The structure of immunoglobulins incorporates several features essential for their participation in the immune response. The two most important of these features are specificity and biologic activity. Specificity is attributed to a defined region of the antibody molecule containing the hypervariable or complementarity-determining region (CDR). This restricts the antibody to combine only with those substances that contain a particular antigenic structure. The existence of a vast array of potential antigenic determinants, which, as we discussed in Chapter 4, are also known as epitopes, prompted the evolution of a system for producing an enormous repertoire of antibody molecules, each of which is capable of combining with a particular antigenic structure. Thus, antibodies collectively exhibit great diversity, in terms of the types of molecular structures with which they are capable of reacting, but individually they exhibit a high degree of specificity, since each is able to react with only one particular antigenic structure.
Despite the large numbers of antigen-specific antibodies, the biologic effects of antigen–antibody reactions are rather few in number. Depending on the nature of the antigen to which the antibody is specific, these include neutralization of toxins; immobilization of microorganisms; neutralization of viral activity; agglutination (clumping together) of microorganisms or of antigenic particles (see Chapter 6); or binding with soluble antigen, leading to the formation of precipitates. The latter is an example of how the adaptive immune system collaborates with the innate immune system since precipitated antigens are readily phagocytized and destroyed by phagocytic cells (see Chapter 2). Other examples of this collaboration, which occurs once antibodies react with antigens, include activation of complement to facilitate the lysis of microorganisms (see Chapters 2 and 14), and complement-mediated opsonization, which also results in phagocytosis and destruction of microbes. Still another important biologic function of antibodies is the ability of certain classes of immunoglobulins to cross the placenta from the mother to the fetus. This is discussed in more detail later in this chapter.
The differences in the various biologic activities of antibodies are attributed to structural properties conferred by the germline-encoded portions of the Ig molecule. Thus, not all antibody molecules are equal in the performance of all of these biologic tasks. In simplest terms, antibody molecules contain structural components that are shared with other antibodies within their class, and an antigen-binding component that is unique to a given antibody. This chapter deals with these structural and biologic properties of immunoglobulins.
Isolation and Characterization of Immunoglobulins
Serum is the antibody-containing component of blood. It is the liquid portion left when blood has been withdrawn and allowed to clot. Unless measures are taken to prevent clotting of blood in the vacutainer in which blood is collected (e.g., the addition of heparin), clotting factors will be activated and cause a cellular clot to form. When the serum component is subjected to electrophoresis (separation in an electrical field) at slightly alkaline pH (8.2), five major components can normally be visualized (see Figure 5.1). The slowest, in terms of migration toward the anode, called γ-globulin, contains the immunoglobulins. This original demonstration entailed the simple comparison of the electrophoretic pattern of antiserum from a hyperimmune rabbit (one that had received multiple immunizations with the same test antigen) before and after the test antigen-specific antibody had been removed by precipitation with the antigen. Only the size of the γ-globulin fraction was diminished by this procedure. Analysis showed that when this fraction was collected separately, all measurable antibodies were contained within it. Later it was shown that antibody activity is present not only in the γ-globulin fraction but also in a slightly more anodic area. Consequently, all globular proteins with antibody activity are generically referred to as immunoglobulins, as exemplified by the γ peak (see Figure 5.1).
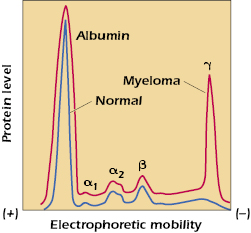
From the broad electrophoretic peaks, it is clear that a heterogeneous collection of immunoglobulin molecules with slightly different charges is present. This heterogeneity was one of the early obstacles in attempts to determine the structure of antibodies, since analytical chemistry requires homogeneous, crystallizable compounds as starting material. This problem was solved, in part, by the discovery of myeloma proteins, which are homogeneous immunoglobulins produced by the progeny of a single plasma cell that has become neoplastic in the malignant disease called multiple myeloma. This is demonstrated by the γ-globulin spike in the electrophoretic pattern of serum proteins of a patient with multiple myeloma (see Figure 5.1). When it became clear that some myeloma proteins bound antigen, it also became apparent that they could be dealt with as typical immunoglobulin molecules.
Another aid to structural studies of antibodies was the discovery of Bence Jones proteins in the urine. These homogeneous proteins, produced in large quantities by some patients with multiple myeloma, are dimers of immunoglobulin κ or λ light chains. They were very useful in the determination of the structure of this portion of the immunoglobulin molecule. Today, the powerful technique of cell–cell hybridization (hybridomas), which allows for the in vitro immortalization of antibody-producing B-cells, permits the production of large quantities of homogeneous preparations of monoclonal antibody of virtually any specificity (see Chapter 6).
Structure of Light and Heavy Chains
Analysis of the structural characteristics of antibody molecules really began in 1959 with two discoveries that, for the first time, revealed that the molecule could be separated into analyzable parts suitable for further study. In England, Porter found that proteolytic treatment with the enzyme papain split the immunoglobulin molecule (molecular weight 150,000 Da) into three fragments of about equal size (see Figure 5.2). Two of these fragments were found to retain the antibody’s ability to bind antigen specifically, although, unlike the intact molecule, they could no longer precipitate the antigen from solution. These two fragments are referred to as Fab (fragment antigen-binding) fragments and are considered to be univalent, possessing one binding site each and being in every way identical to each other. The third fragment could be crystallized out of solution, a property indicative of its apparent homogeneity. This fragment is called the Fc fragment (fragment crystallizable). It cannot bind antigen, but as was subsequently shown, it is responsible for the biologic functions of the antibody molecule after antigen has been bound to the Fab part of the intact molecule.
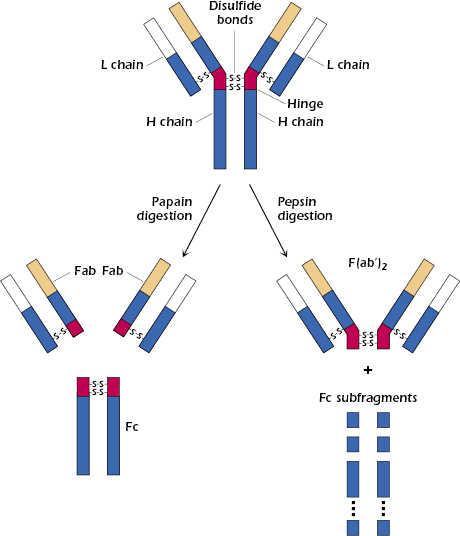
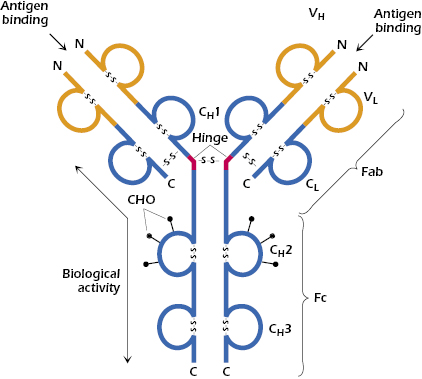
At about the same time, Edelman in the United States discovered that when γ-globulin was extensively reduced by treatment with mercaptoethanol (a reagent that breaks disulfide bonds), the molecule fell apart into four chains: two identical light chains with a molecular weight of about 22,000 Da each and two others of about 53,000 Da each. The larger molecules were designated heavy chains (often abbreviated as H chains) and the smaller ones, light chains (often abbreviated as L chains). On the basis of these results, the basic unit structure of immunoglobulin molecules, as depicted in Figure 5.2, was proposed. This model was subsequently shown to be essentially correct, and Porter and Edelman shared the Nobel Prize for the elucidation of antibody structure. Thus, all immunoglobulin molecules consist of a basic unit of four polypeptide chains, two identical heavy chains and two identical light chains, held together by several disulfide bonds. It should be noted that papain digestion of the immunoglobulin molecule results in cleavage N-terminally to the disulfide bridge between the heavy chains at the hinge region, yielding two monovalent Fab fragments and an Fc fragment. On the other hand, pepsin digestion results in cleavage C-terminally to the disulfide bridge, resulting in a divalent fragment referred to as F(ab′)2, consisting of two Fab fragments joined by the disulfide bond and several Fc subfragments. A more detailed diagram of a generic immunoglobulin molecule, consisting of two glycosylated heavy chains and two light chains, is shown in Figure 5.3. Note that in addition to the interchain disulfide bonds that hold the chains together, the heavy and light chains each contain intrachain disulfide bonds to create the immunoglobulin-fold domains to create the antiparallel β-pleated sheet structure characteristic of antibody molecules. As discussed later in this chapter, other molecules belonging to the so-called immunoglobulin superfamily share this structural feature.
As one might expect, immunoglobulins of one species are immunogenic in another species. In other words, the use of immunoglobulins of a given species as immunogens in another species allows for the production of antisera that can then be used to investigate the various features of different immunoglobulin chains. This serologic approach to studying immunoglobulins, together with several biochemical strategies, revealed important insights into the structural properties of these molecules. For example, it demonstrated that almost all species studied have two major classes of light chains, called κ and λ. Any one individual of a species produces both types of light chain, but the ratio of κ chains to λ chains varies with the species (mouse: 95% κ; human: 60% κ). However, in any one immunoglobulin molecule, the light chains are always either both κ or both λ, never one of each.
Another important characteristic of immunoglobulins revealed in this early work was that the heavy chains of immunoglobulins of virtually all species studied can be divided into five different classes or isotypes. The five classes of immunoglobulins include IgM, IgD, IgG, IgA, and IgE. These are distinguished from one another based upon so-called constant regions of the heavy chains, which differ from one another with regard to their protein sequences, carbohydrate content, and size. As noted earlier, these portions of the various Ig classes also confer different biologic functions associated with each isotype. The Ig heavy chains, whose constant regions are derived from Ig heavy chain genes (discussed in detail in Chapter 7) are designated with Greek letters as shown in Table 5.1.
Table 5.1. Immunoglobulin Heavy Chain Isotopes
| Immunoglobulin | Heavy chain gene |
|---|---|
| IgM | μ |
| IgD | δ |
| IgG | γ |
| IgA | α |
| IgE | ε |
Therefore, the genes encoding these constant (C) regions responsible for the μ, δ, γ, α, and ε heavy chains are called Cμ, Cδ, Cγ, Cα, and Cε, respectively. Any individual of a species makes all five Ig isotypes, in proportions characteristic of the species, but, just as the case with light chains described above, in any one antibody molecule both heavy chains are always identical (e.g., 2γ or 2ε, etc.). Thus, an antibody molecule of the IgG class could have the structure κ2γ2 with two identical kappa light chains and two identical gamma heavy chains. Alternatively, it could have the structure λ2γ2 with two identical lambda light chains and two identical γ heavy chains. In contrast, an antibody of the IgE class could have the structure κ2ε2 or λ2ε2. In each case, it is the nature of the heavy chains that confers on the molecule its unique biologic properties, such as its half-life in the circulation, its ability to bind to certain receptors, and its ability to activate complement (see Chapter 14) on combination with antigen.
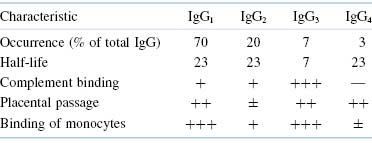
Further characterization of these isotypes by specific antisera has led to the designation of several subclasses that have more subtle differences among themselves. Thus, the major class of human IgG can be subdivided into the subclasses IgG1, IgG2, IgG3, and IgG4. IgA has been divided similarly into two subclasses, IgA1 and IgA2. The subclasses differ from one another in numbers and arrangement of interchain disulfide bonds, as well as by alterations in other structural features. These alterations, in turn, produce some changes in functional properties that will be discussed later.
Domains
Early in the study of the structure of immunoglobulins, it became apparent that in addition to interchain disulfide bonds that hold together light and heavy chains, as well as the two heavy chains, intrachain disulfide bonds exist that form loops within the chain. The globular structure of immunoglobulins, and the ability of enzymes to cleave these molecules at very restricted positions into large entities instead of degrading them to oligopeptides and amino acids, is indicative of a very compact structure. Furthermore, the presence of intrachain disulfide bonds at regular, approximately equal intervals of about 100–110 amino acids leads to the prediction that each loop in the peptide chains should form a compactly folded globular domain. In fact, light chains have two domains each, and heavy chains have four or five domains, separated by a short unfolded stretch (see Figure 5.3). These configurations have been confirmed by direct observation and by genetic analysis (see Chapter 7).
Immunoglobulin molecules are assemblies of separate domains, each centered on a disulfide bond, and each having so much homology with the others as to suggest that they evolved from a single ancestral gene, which duplicated itself several times and then changed its amino acid sequence to enable the resultant different domains to fulfill different functions. Each domain is designated by a letter that indicates whether it is on a light chain or a heavy chain and a number that indicates its position. As we shall soon discuss in more detail, the first domain on light and heavy chains is highly variable, in terms of amino acid sequence, from one antibody to the next, and it is designated VL or VH accordingly (see Figure 5.3). The second and subsequent domains on both heavy chains are much more constant in amino acid sequence and are designated CH1, CH2, and CH3 (Figure 5.3). In addition to their interchain disulfide bonding, the globular domains bind to each other in homologous pairs, largely by hydrophobic interactions, as follows: VHVL, CH1CL, CH2CH2, and CH3CH3.
Hinge Region
The hinge region of immunoglobulins is composed of a short segment of amino acids (relatively long in the case of IgD and IgE) and is found between the CH1 and CH2 regions of the heavy chains (see Figure 5.3). This segment is made up predominantly of cysteine and proline residues. The cysteines are involved in formation of interchain disulfide bonds, and the proline residues prevent folding in a globular structure. This region of the heavy chain provides an important structural characteristic of immunoglobulins. It permits flexibility between the two Fab arms of the Y-shaped antibody molecule. It allows the two Fab arms to open and close to accommodate binding to two identical antigenic epitopes, separated by a fixed distance, as might be found on the surface of a bacterium. Additionally, since this stretch of amino acids is open and as accessible as any other nonfolded peptide, it can be cleaved by proteases, such as papain, to generate the Fab and Fc fragments described above (see Figure 5.2).
Variable Region
As we have discussed earlier, in contrast to the constant region of immunoglobulins, the variable region of immunoglobulins constitutes the part of the molecule that binds to the antigen for which the antibody is specific. A major problem for immunologists was to determine how so many individual specificities, which are required to meet the enormous variety of antigenic challenges, are generated from the variable region gene. As we shall see in Chapter 7, this issue has been largely resolved and is explained by the phenomenon of gene rearrangement associated with B cells (and T cells for the TCR as we shall in Chapter 10). We will briefly introduce the concept of hypervariability regions of immunoglobulins in this section, as it relates to the concept of antibody specificity, since it is important for topics covered later in this chapter.
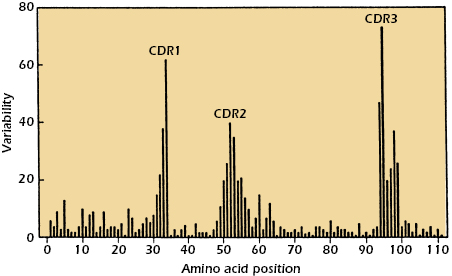
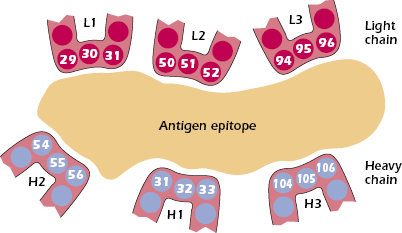
When the amino acid sequences of immunoglobulin molecules derived from sera or urine of individuals suffering with multiple myeloma were examined, significant insights into the antigen-binding region of antibodies were obtained. Why were these sera and urine samples chosen for examination? As discussed earlier in this chapter, the sera in multiple myeloma patients often contains copious amounts of immunoglobulin molecules, all identical in structure and specificity by virtue of their production by the neoplastic plasma cells causing the disease. In addition, urine from such patients contains large amounts of light chain molecules associated with these myeloma proteins (i.e., Bence Jones proteins). Using these sera and urine samples, it was found that the greatest variability in sequence existed in the N-terminal 110 amino acids of both the light and heavy chains. Kabat and Wu compared the amino acid sequences of many different VL and VH regions. They plotted the variability in the amino acids at each position in the chain and showed that the greatest amount of variability (defined as the ratio of the number of different amino acids at a given position to the frequency of the most common amino acid at that position) occurred in three regions of the light and heavy chains. These regions are called hypervariable regions. The less variable stretches, which occur between these hypervariable regions, are called framework regions. It is now clear that the hypervariable regions participate in the binding with antigen and form the region complementary in structure to the antigen. Consequently, hypervariability regions are termed complementarity-determining regions (CDRs) of the light and heavy chains: CDR1, CDR2, and CDR3 (see Figure 5.4).
The hypervariable regions, although separated in the linear, two-dimensional model of the peptide chains, are actually brought together in the folded form of the intact antibody molecule, and together they constitute the combining site, which is complementary to the epitope (Figure 5.5). The variability in these CDRs provides the diversity in the shape of the combining site that is required for the function of antibodies of different specificities. All the known forces involved in antigen–antibody interactions are weak, noncovalent interactions (e.g., ionic, hydrogen-bonding, van der Walls forces, and hydrophobic interactions). It is therefore necessary that there be a close fit between antigen and antibody over a sufficiently large region to allow a total binding force that is adequate for stable interaction. Contributions to this binding interaction by both heavy and light chains are involved in the overall association between epitope and antibody.
It should now be apparent that two antibody molecules with different antigenic specificities must have different amino acid sequences in their hypervariable regions and that those with similar sequences will generally have similar specificities. However, it is possible for two antibodies with different amino acid sequences to have specificity to the same epitope. In this case, the binding affinities of the antibodies with the epitope will probably be different because there will be differences in the number and types of binding forces available to bind identical antigens to the different binding sites of the two antibodies.
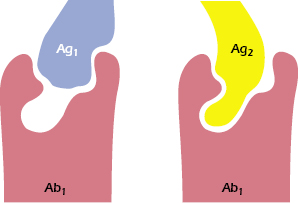
An additional source of variability involves the size of the combining site on the antibody, which is usually (but not always) considered to take the form of a depression or cleft. In some instances, especially when small, hydrophobic haptens are involved, the epitopes do not occupy the entire combining site, yet they achieve sufficient affinity of binding. It has been shown that antibodies specific for such a hapten may, in fact, react with other antigens that have no obvious similarity to the hapten (e.g., dinitrophenol and sheep red cells). These dissimilar antigens bind either to a larger area or to a different area of the combining site on the antibody (see Figure 5.6). Thus, a particular antibody-combining site may have the ability to combine with two (or more) apparently diverse epitopes, a property called redundancy. The ability of a single antibody molecule to cross-react with an unknown number of epitopes may reduce the number of different antibodies needed to defend an individual against the range of antigenic challenges.
Immunoglobulin Variants
Isotypes
We have already introduced the term isotype in this chapter. Why has the immune system evolved to provide this level of immunoglobulin diversity? To optimize humoral immune defenses against infectious pathogens and other foreign substances, a variety of mechanisms, each dependent on a somewhat different property or function of an immunoglobulin molecule, has developed. Thus, when a specific antibody molecule combines with a specific antigen such as a pathogen, several different effector mechanisms come into play. These different mechanisms derive from the different classes of immunoglobulin (isotypes), each of which may combine with the same epitope but each of which triggers a different biologic response. These differences result from structural variations in the constant regions of the heavy chains, which have generated domains that mediate a variety of functions. A summary of the properties of the immunoglobulin classes is given in Tables 5.2 and 5.3.
Table 5.2. Most Important Features of Immunoglobulin Isotopes
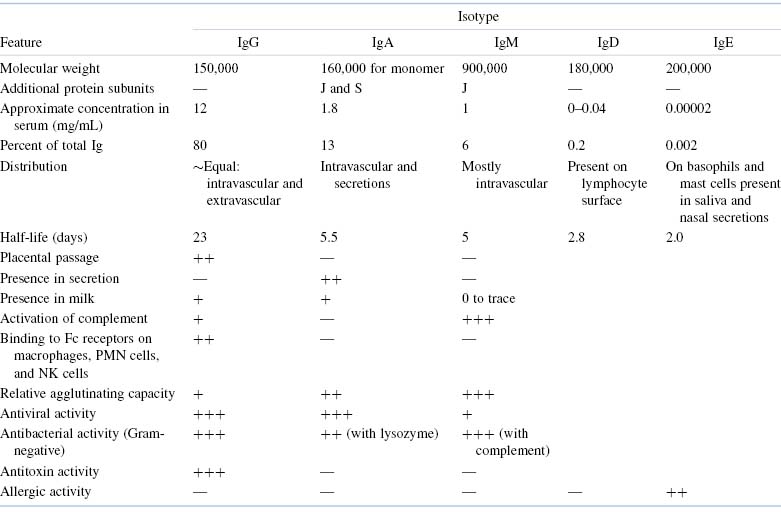
Table 5.3. Important Differences Among Human IgG Subclasses
Allotypes
Another form of variation in the structure of immunoglobulins is allotypy. It is based on genetic differences between individuals. In other words, different allelic forms
Related posts:
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


