Treatment
Treatments should be given “not because they ought to work, but because they do work.”
—L.H. Opie 1980
KEY WORDS
Hypotheses
Treatment
Intervention
Comparative effectiveness
Experimental studies
Clinical trials
Randomized controlled trials
Equipoise
Inclusion criteria
Exclusion criteria
Comorbidity
Large simple trials
Practical clinical trials
Pragmatic clinical trials
Hawthorne effect
Placebo
Placebo effect
Random allocation
Randomization
Baseline characteristics
Stratified randomization
Compliance
Adherence
Run-in period
Cross-over
Blinding
Masking
Allocation concealment
Single-blind
Double-blind
Open label
Composite outcomes
Health-related quality of life
Health status
Efficacy trials
Effectiveness trials
Intention-to-treat analysis
Explanatory analyses
Per-protocol
Superiority trials
Non-inferiority trials
Inferiority margin
Cluster randomized trials
Cross-over trials
Trials of N = 1
Confounding by indication
Phase I trials
Phase II trials
Phase III trials
Postmarketing surveillance
After the nature of a patient’s illness has been established and its expected course predicted, the next question is, what can be done about it? Is there a treatment that improves the outcome of disease? This chapter describes the evidence used to decide whether a well-intentioned treatment is actually effective.
IDEAS AND EVIDENCE
The discovery of effective new treatments requires both rich sources of promising possibilities and rigorous ways of establishing that the treatments are, in fact, effective (Fig. 9.1).
Ideas
Ideas about what might be a useful treatment arise from virtually any activity within medicine. These ideas are called hypotheses to the extent that they are assertions about the natural world that are made for the purposes of empiric testing.
Some therapeutic hypotheses are suggested by the mechanisms of disease at the molecular level. Drugs for antibiotic-resistant bacteria are developed through knowledge of the mechanism of resistance and hormone analogues are variations on the structure of native hormones. Other hypotheses about treatments have come from astute observations by clinicians, shared with their colleagues in case reports. Others are discovered by accident: The drug minoxidil, which was developed for hypertension, was found to improve male pattern baldness; and tamoxifen, developed for contraception, was found to prevent breast cancer in high-risk women. Traditional medicines, some of which are supported by centuries of experience,
may be effective. Aspirin, atropine, and digitalis are examples of naturally occurring substances that have become established as orthodox medicines after rigorous testing. Still other ideas come from trial and error. Some anticancer drugs have been found by methodically screening huge numbers of substances for activity in laboratory models. Ideas about treatment, but more often prevention, have also come from epidemiologic studies of populations. The Framingham Study, a cohort study of risk factors for cardiovascular diseases, was the basis for clinical trials of lowering blood pressure and serum cholesterol.
may be effective. Aspirin, atropine, and digitalis are examples of naturally occurring substances that have become established as orthodox medicines after rigorous testing. Still other ideas come from trial and error. Some anticancer drugs have been found by methodically screening huge numbers of substances for activity in laboratory models. Ideas about treatment, but more often prevention, have also come from epidemiologic studies of populations. The Framingham Study, a cohort study of risk factors for cardiovascular diseases, was the basis for clinical trials of lowering blood pressure and serum cholesterol.
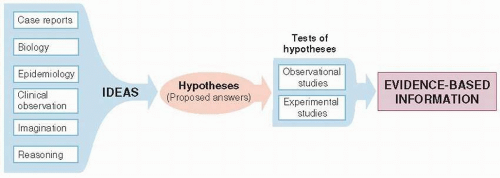 Figure 9.1 ▪ Ideas and evidence. |
Testing Ideas
Some treatment effects are so prompt and powerful that their value is self-evident even without formal testing. Clinicians do not have reservations about the effectiveness of antibiotics for bacterial meningitis, or diuretics for edema. Clinical experience is sufficient.
In contrast, many diseases, including most chronic diseases, involve treatments that are considerably less dramatic. The effects are smaller, especially when an effective treatment is tested against another effective treatment. Also outcomes take longer to develop. It is then necessary to put ideas about treatments to a formal test, through clinical research, because a variety of circumstances, such as coincidence, biased comparisons, spontaneous changes in the course of disease, or wishful thinking, can obscure the true relationship between treatment and outcomes.
When knowledge of the pathogenesis of disease, based on laboratory models or physiologic studies in humans, has become extensive, it is tempting to predict effects in humans on this basis alone. However, relying solely on current understanding of mechanisms without testing ideas using strong clinical research on intact humans can lead to unpleasant surprises.
Example
Control of elevated blood sugar has been a keystone in the care of patients with diabetes mellitus, in part to prevent cardiovascular complications. Hyperglycemia is the most obvious metabolic abnormality in patients with diabetes. Cardiovascular disease is common in patients with diabetes, and observational studies have shown an association between elevated blood sugar and cardiovascular events. To study the effects of tight control of blood sugar on cardiovascular events, the ACCORD Trial randomized 10,251 patients with type 2 diabetes mellitus and other risk factors for cardiovascular disease to either intensive therapy or usual care (1). Glucose control was substantially better in the intensive therapy group but surprisingly, after 3.7 years in the trial, patients assigned to intensive therapy had 21% more deaths. They also had more hypoglycemic episodes and more weight gain. Results were similar after 5 years of follow-up. Increased mortality with “tight” control, which was contrary to conventional thinking about diabetes (but consistent with other trial results), has prompted less aggressive goals for blood glucose control and more aggressive treatment of other risk factors for cardiovascular disease, such as blood pressure, smoking, and dyslipidemia.
This study illustrates how treatments that make good sense, based on what is known about the disease at the time, may be found to be ineffective when put to a rigorous test in humans. Knowledge of pathogenesis,
worked out in laboratory models, may be disappointing in human studies because the laboratory studies are in highly simplified settings. They usually exclude or control for many real-world influences on disease such as variation in genetic endowment, the physical and social environment, and individual behaviors and preferences.
worked out in laboratory models, may be disappointing in human studies because the laboratory studies are in highly simplified settings. They usually exclude or control for many real-world influences on disease such as variation in genetic endowment, the physical and social environment, and individual behaviors and preferences.
Clinical experience and tradition also need to be put to a test. For example, bed rest has been advocated for a large number of medical conditions. Usually, there is a rationale for it. For example, it has been thought that the headache following lumbar puncture might result from a leak of cerebrospinal fluid through the needle track causing stretching of the meninges. However, a review of 39 trials of bed rest for 15 different conditions found that outcome did not improve for any condition. Outcomes were worse with bed rest in 17 trials, including not only lumbar puncture, but also acute low back pain, labor, hypertension during pregnancy, acute myocardial infarction, and acute infectious hepatitis (2).
Of course, it is not always the case that ideas are debunked. The main point is that promising treatments have to be tested by clinical research rather than accepted into the care of patients on the basis of reasoning alone.
STUDIES OF TREATMENT EFFECTS
Treatment is any intervention that is intended to improve the course of disease after it is established. Treatment is a special case of interventions in general that might be applied at any point in the natural history of disease, from disease prevention to palliative care at the end of life. Although usually thought of as medications, surgery, or radiotherapy, health care interventions can take any form, including relaxation therapy, laser surgery, or changes in the organization and financing of health care. Regardless of the nature of a well-intentioned intervention, the principles by which it is judged superior to other alternatives are the same.
Comparative effectiveness is a popular name for a not-so-new concept, the head-to-head comparison of two or more interventions (e.g., drugs, devices, tests, surgery, or monitoring), all of which are believed to be effective and are current options for care. Comparison is not just for effectiveness, but also for all clinically important end results of the interventions—both beneficial and harmful. Results can help clinicians and patients understand all of the consequences of choosing one or another course of action when both have been considered reasonable alternatives.
Observational and Experimental Studies of Treatment Effects
Two general methods are used to establish the effects of interventions: observational and experimental studies. The two differ in their scientific strength and feasibility.
In observational studies of interventions, investigators simply observe what happens to patients who for various reasons do or do not get exposed to an intervention (see Chapters 5, 6, 7). Observational studies of treatment are a special case of studies of prognosis in general, in which the prognostic factor of interest is a therapeutic intervention. What has been said about cohort studies applies to observational studies of treatment as well. The main advantage of these studies is feasibility. The main drawback is the possibility that there are systematic differences in treatment groups, other than the treatment itself, that can lead to misleading conclusions about the effects of treatment.
Experimental studies are a special kind of cohort study in which the conditions of study—selection of treatment groups, nature of interventions, management during follow-up, and measurement of outcomes-are specified by the investigator for the purpose of making unbiased comparisons. These studies are generally referred to as clinical trials. Clinical trials are more highly controlled and managed than cohort studies. The investigators are conducting an experiment, analogous to those done in the laboratory. They have taken it upon themselves (with their patients’ permission) to isolate for study the unique contribution of one factor by holding constant, as much as possible, all other determinants of the outcome.
Randomized controlled trials, in which treatment is randomly allocated, are the standard of excellence for scientific studies of the effects of treatment. They are described in detail below, followed by descriptions of alternative ways of studying the effectiveness of interventions.
RANDOMIZED CONTROLLED TRIALS
The structure of a randomized controlled trial is shown in Figure 9.2. All elements are the same as for a cohort study except that treatment is assigned by randomization rather than by physician and patient choice. The “exposures” are treatments, and the “outcomes” are any possible end result of treatment (such as the 5 Ds described in Table 1.2).
The patients to be studied are first selected from a larger number of patients with the condition of
interest. Using randomization, the patients are then divided into two (or more) groups of comparable prognosis. One group, called the experimental group, is exposed to an intervention that is believed to be better than current alternatives. The other group, called a control (or comparison) group, is treated the same in all ways except that its members are not exposed to the experimental intervention. Patients in the control group may receive a placebo, usual care, or the current best available treatment. The course of disease is then recorded in both groups, and differences in outcome are attributed to the intervention.
interest. Using randomization, the patients are then divided into two (or more) groups of comparable prognosis. One group, called the experimental group, is exposed to an intervention that is believed to be better than current alternatives. The other group, called a control (or comparison) group, is treated the same in all ways except that its members are not exposed to the experimental intervention. Patients in the control group may receive a placebo, usual care, or the current best available treatment. The course of disease is then recorded in both groups, and differences in outcome are attributed to the intervention.
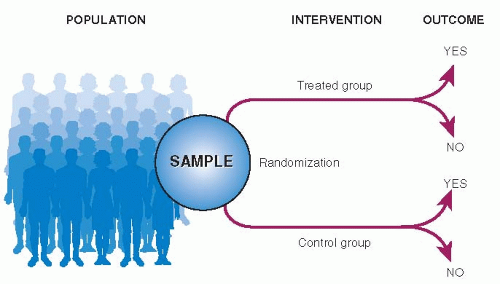 Figure 9.2 ▪ The structure of a randomized controlled trial. |
The main reason for structuring clinical trials in this way is to avoid confounding when comparing the respective effects of two or more kinds of treatments. The validity of clinical trials depends on how well they have created equal distribution of all determinants of prognosis, other than the one being tested, in treated and control patients.
Individual elements of clinical trials are described in detail in the following text.
Ethics
Under what circumstances is it ethical to assign treatment at random, rather than as decided by the patient and physician? The general principle, called equipoise, is that randomization is ethical when there is no compelling reason to believe that either of the randomly allocated treatments is better than the other. Usually it is believed that the experimental intervention might be better than the control but that has not been conclusively established by strong research. The primary outcome must be benefit; treatments cannot be randomly allocated to discover whether one is more harmful than the other. Of course, as with any human research, patients must fully understand the consequences of participating in the study, know that they can withdraw at any time without compromising their health care, and freely give their consent to participate. In addition, the trial must be stopped whenever there is convincing evidence of effectiveness, harm, or futility in continuing.
Sampling
Clinical trials typically require patients to meet rigorous inclusion and exclusion criteria. These are intended to increase the homogeneity of patients in the study, to strengthen internal validity, and to make it easier to distinguish the “signal” (treatment effect) from the “noise” (bias and chance).
Among the usual inclusion criteria is that patients really do have the condition being studied. To be on the safe side, study patients must meet strict diagnostic criteria. Patients with unusual, mild, or equivocal manifestations of disease may be left out in the process, restricting generalizability.
Of the many possible exclusion criteria, several account for most of the losses:
Patients with comorbidity (diseases other than the one being studied) are typically excluded because the care and outcome of these other diseases can muddy the contrast between experimental and comparison treatments and their outcomes.
Patients are excluded if they are not expected to live long enough to experience the outcome events of interest.
Patients with contraindications to one of the treatments cannot be randomized.
Patients who refuse to participate in a trial are excluded, for ethical reasons described earlier in the chapter.
Patients who do not cooperate during the early stages of the trial are also excluded. This avoids wasted effort and the reduction in internal validity that occurs when patients do not take their assigned intervention, move in and out of treatment groups, or leave the trial altogether.
For these reasons, patients in clinical trials are usually a highly selected, biased sample of all patients with the condition of interest. As heterogeneity is restricted, the internal validity of the study is improved; in other words, there is less opportunity for differences in outcome that are not related to treatment itself. However, exclusions come at the price of diminished generalizability: Patients in the trial are not like most other patients seen in day-to-day care.
Example
Figure 9.3 summarizes how patients were selected for a randomized controlled trial of asthma management (3). Investigators invited 1,410 patients with asthma in 81 general practices in Scotland to participate. Only 458 of those invited, about one-third, agreed to participate and could be contacted. An additional 199 were excluded, mainly because they did not meet eligibility criteria, leaving 259 patients (18% of those invited) to be randomized. Although the study invited patients from community practices, those who actually participated in the trial were highly selected and perhaps unlike most patients in the community.
Because of the high degree of selection in trials, it may require considerable faith to generalize the results of clinical trials to ordinary practice settings.
If there are not enough patients with the disease of interest, at one time and place, to carry out a scientifically sound trial, then sampling can be from multiple sites with common inclusion and exclusion criteria. This is done mainly to achieve adequate sample size, but it also increases generalizability, to the extent that the sites are somewhat different from each other.
Large simple trials are a way of overcoming the generalizability problem. Trial entry criteria are simplified so that most patients developing the study condition are eligible. Participating patients have to have accepted random allocation of treatment, but their care is otherwise the same as usual, without a great deal of extra testing that is part of some trials. Follow-up is for a simple, clinically important outcome, such as discharge from the hospital alive. This approach not only improves generalizability, it also makes it easier to recruit large numbers of participants at a reasonable cost so that moderate effect sizes (large effects are unlikely for most clinical questions) can be detected.
Practical clinical trials (also called pragmatic clinical trials) are designed to answer real-world questions in the actual care of patients by including the kinds of patients and interventions found in ordinary patient care settings.
Example
Severe ankle sprains are a common problem among patients visiting emergency departments. Various treatments are in common use. The Collaborative Ankle Support Trial Group enrolled 584 patients with severe ankle sprain in eight emergency departments in the United Kingdom in a randomized trial of four commonly used treatments: tubular compression bandage and three types of mechanical support (4). Quality of ankle function at 3 months was best after a below-the-knee cast was used for 10 days and worst when a tubular compression bandage was used; the tubular compression bandage was being used in 75% of centers in the United Kingdom at the time. Two less effective forms of mechanical support were several times more expensive than the cast. All treatment groups improved over time and there was no difference in outcome among them at 9 months.
Practical trials are different from typical efficacy trials where, in an effort to increase internal validity, severe restrictions are applied to enrollment, intervention, and adherence, limiting the relevance of their results for usual patient care decisions. Large simple trials may be of practical questions too, but practical trials need not be so large.
Intervention
The intervention can be described in relation to three general characteristics: generalizability, complexity, and strength.
First, is the intervention one that is likely to be implemented in usual clinical practice? In an effort
to standardize the intervention so that it can be easily described and reproduced in other settings, investigators may cater to their scientific, not their clinical colleagues by studying treatments that are not feasible in usual practice.
to standardize the intervention so that it can be easily described and reproduced in other settings, investigators may cater to their scientific, not their clinical colleagues by studying treatments that are not feasible in usual practice.
 Figure 9.3 ▪ Sampling of patients for a randomized controlled trial of asthma management. (Data from Hawkins G, McMahon AD, Twaddle S, et al. Stepping down inhaled corticosteroids in asthma: randomized controlled trial. BMJ 2003;326: 1115-1121.) |
Second, does the intervention reflect the normal complexity of real-world treatment? Clinicians regularly construct treatment plans with many components. Single, highly specific interventions make for tidy science because they can be described precisely and applied in a reproducible way, but they may have weak effects. Multifaceted interventions, which are often more effective, are also amenable to careful evaluation as long as their essence can be communicated and applied in other settings. For example, a randomized trial of fall prevention in acute care hospitals studied the effects of a fall risk assessment scale, with interventions tailored to each patient’s specific risks (5).
Third, is the intervention in question sufficiently different from alternative managements that it is reasonable to expect that the outcome will be affected? Some diseases can be reversed by treating a single, dominant cause. Treating hyperthyroidism with radioisotope ablation or surgery is one example. However, most diseases arise from a combination of factors acting in concert. Interventions that change only one of them, and only a small amount, cannot be expected to result in strong treatment effects. If the conclusion of a trial evaluating such interventions is that a new treatment is not effective when used alone, it should come as no surprise. For this reason, the first trials of a new treatment tend to enroll those patients who are most likely to respond to treatment and to maximize dose and compliance.
Comparison Groups
The value of an intervention is judged in relation to some alternative course of action. The question is not only whether a comparison is used, but also how appropriate it is for the research question. Results can be measured against one or more of several kinds of comparison groups.
No Intervention. Do patients who are offered the experimental treatment end up better off than those offered nothing at all? Comparing treatment with no treatment measures the total effects of care and of being in a study, both specific and nonspecific.
Being Part of a Study. Do treated patients do better than other patients who just participate in a study? A great deal of special attention is directed toward patients in clinical trials. People have a tendency to change their behavior when they are the target of special interest and attention because of the study, regardless of the specific nature of the intervention they might be receiving. This phenomenon is called the Hawthorne effect. The reasons are not clear, but some seem likely: Patients want to please them and make them feel successful. Also, patients who volunteer for trials want to do their part to see that “good” results are obtained.
Usual Care. Do patients given the experimental treatment do better than those receiving usual care— whatever individual doctors and patients decide? This is the only meaningful (and ethical) question if usual care is already known to be effective.
Placebo Treatment. Do treated patients do better than similar patients given a placebo— an intervention intended to be indistinguishable (in physical appearance, color, taste, or smell) from the active treatment but does not have a specific, known mechanism of action? Sugar pills and saline injections are examples of placebos. It has been shown that placebos, given with conviction, relieve severe, unpleasant symptoms, such as postoperative pain, nausea, or itching, in about one-third of patients, a phenomenon called the placebo effect. Placebos have the added advantage of making it difficult for study patients to know which intervention they have received (see “Blinding” in the following text).
Another Intervention. The comparator may be the current best treatment. The point of a “comparative effectiveness” study is to find out whether a new treatment is better than the one in current use.
Changes in outcome related to these comparators are cumulative, as diagrammed in Figure 9.4.
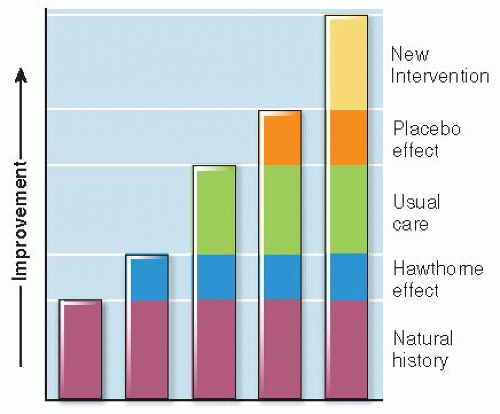 Figure 9.4 ▪ Total effects of treatment are the sum of spontaneous improvement (natural history) as well as nonspecific and specific responses. |
Allocating Treatment
To study the effects of a clinical intervention free of confounding, the best way to allocate patients to treatment groups is by means of random allocation (also referred to as randomization). Patients are assigned to either the experimental or the control treatment by one of a variety of disciplined procedures—analogous to flipping a coin—whereby each patient has an equal (or at least known) chance of being assigned to any one of the treatment groups.
Random allocation of patients is preferable to other methods of allocation because only randomization has the ability to create truly comparable groups. All factors related to prognosis, regardless of whether they are known before the study takes place or have been measured, tend to be equally distributed in the comparison groups.
In the long run, with a large number of patients in a trial, randomization usually works as just described. However, random allocation does not guarantee that the groups will be similar; dissimilarities can arise by chance alone, particularly when the number of patients randomized is small. To assess whether “bad luck” has occurred, authors of randomized controlled trials often present a table comparing the frequency in the treated and control groups of a variety of characteristics, especially those known to be related to outcome. These are called baseline characteristics because they are present before randomization and, therefore, should be equally distributed in the treatment groups.
Example
Table 9.1 shows some of the baseline characteristics for a study of liberal versus restrictive blood transfusion in high-risk patients after hip surgery. The 2,016 enrolled patients were at increased risk because of risk factors for cardiovascular disease or anemia after surgery. The primary outcome was death or the inability to walk across a room without human assistance (6). Table 9.1 lists several characteristics already known, from other studies or clinical experience, to be related to one or both of these outcomes. Each of these characteristics was similarly distributed in the two treatment groups. These comparisons, at least for the several characteristics that were measured, strengthen the belief that randomization was carried out properly and actually produced groups with similar risk for death or inability to walk unassisted.
Table 9.1 Example of a Table Comparing Baseline Characteristics: A Randomized Trial of Liberal versus Restrictive Transfusion in High-Risk Patients after Hip Surgery | ||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||
Related posts:

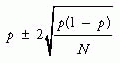


Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


