There is a broad consensus that cancer is, in essence, a genetic disease, and that accumulation of molecular alterations in the genome of somatic cells is the basis of cancer progression (Fig. 1.1).1 In the past 10 years, the availability of the human genome sequence and progress in DNA sequencing technologies has dramatically improved knowledge of this disease. These new insights are trans-forming the field of oncology at multiple levels:
The genomic maps are redesigning the tumor taxonomy by moving it from a histologic- to a genetic-based level.
The success of cancer drugs designed to target the molecular alterations underlying tumorigenesis has proven that somatic genetic alterations are legitimate targets for therapy.
Tumor genotyping is helping clinicians individualize treat-ments by matching patients with the best treatment for their tumors.
Tumor-specific DNA alterations represent highly sensitive bio-markers for disease detection and monitoring.
Finally, the ongoing analyses of multiple cancer genomes will identify additional targets, whose pharmacologic exploitation will undoubtedly result in new therapeutic approaches.
This chapter will review the progress that has been made in understanding the genetic basis of sporadic cancers. An emphasis will be placed on an introduction to novel integrated genomic approaches that allow a comprehensive and systematic evaluation of genetic alterations that occur during the progression of cancer. Using these powerful tools, cancer research, diagnosis, and treatment are poised for a transformation in the next years.
CANCER GENES AND THEIR MUTATIONS
Cancer genes are broadly grouped into oncogenes and tumor suppressor genes. Using a classical analogy, oncogenes can be compared to a car accelerator, so that a mutation in an oncogene would be the equivalent of having the accelerator continuously pressed.2 Tumor suppressor genes, in contrast, act as brakes,2 so that when they are not mutated, they function to inhibit tumorigenesis. Oncogene and tumor suppressor genes may be classified by the nature of their somatic mutations in tumors. Mutations in oncogenes typically occur at specific hotspots, often affecting the same codon or clustered at neighboring codons in different tumors.1 Furthermore, mutations in oncogenes are almost always missense, and the mutations usually affect only one allele, making them heterozygous. In contrast, tumor suppressor genes are usually mutated throughout the gene; a large number of the mutations may truncate the encoded protein and generally affect both alleles, causing loss of heterozygosity (LOH). Major types of somatic mutations present in malignant tumors include nucleotide substitutions, small insertions and deletions (indels), chromosomal rearrangements, and copy number alterations.
IDENTIFICATION OF CANCER GENES
The completion of the Human Genome Project marked a new era in biomedical sciences.3 Knowledge of the sequence and organization of the human genome now allows for the systematic analysis of the genetic alterations underlying the origin and evolution of tumors. Before elucidation of the human genome, several cancer genes, such as KRAS, TP53, and APC, were successfully discovered using approaches based on an oncovirus analysis, linkage studies, LOH, and cytogenetics.4,5 The first curated version of the Human Genome Project was released in 2004,3 and provided a sequence-based map of the normal human genome. This information, together with the construction of the HapMap, which contains single nucleotide polymorphisms (SNP), and the underlying genomic structure of natural human genomic variation,6,7 allowed an extraordinary throughput in cataloging somatic mutations in cancer. These projects now offer an unprecedented opportunity: the identification of all the genetic changes associated with a human cancer. For the first time, this ambitious goal is within reach of the scientific community. Already, a number of studies have demonstrated the usefulness of strategies aimed at the systematic identification of somatic mutations associated with cancer progression. Notably, the Human Genome Project, the HapMap project, as well as the candidate and family gene approaches (described in the following paragraphs), utilized capillary-based DNA sequencing (first-generation sequencing, also known as Sanger sequencing).8Figure 1.2 clearly illustrates the developments in the search of cancer genes, its increased pace, as well as the most relevant findings in this field.
Cancer Gene Discovery by Sequencing Candidate Gene Families
The availability of the human genome sequence provides new opportunities to comprehensively search for somatic mutations in cancer on a larger scale than previously possible. Progress in the field has been closely linked to improvements in the throughput of DNA analysis and in the continuous reduction in sequencing costs. What follows are some of the achievements in this research area, as well as how they affected knowledge of the cancer genome.
A seminal work in the field was the systematic mutational profiling of the genes involved in the RAS-RAF pathway in multiple tumors. This candidate gene approach led to the discovery that BRAF is frequently mutated in melanomas and is mutated at a lower frequency in other tumor types.9 Follow-up studies quickly revealed that mutations in BRAF are mutually exclusive with alterations in KRAS,9,10 genetically emphasizing that these genes function in the same pathway, a concept that had been previously demonstrated in lower organisms such as Caenorhabditis elegans and Drosophila melanogaster.11,12
In 2003, the identification of cancer genes shifted from a candidate gene approach to the mutational analyses of gene families. The first gene families to be completely sequenced were those that involved protein13,14 and lipid phosphorylation.15 The rationale for initially focusing on these gene families was threefold:
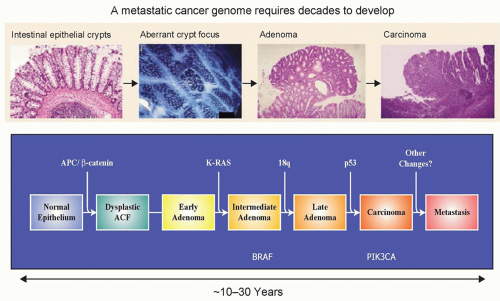
Figure 1.1 Schematic representation of the genomic and histopathologic steps associated with tumor progression: from the occurrence of the initiating mutation in the founder cell to metastasis formation. It has been convincingly shown that the genomic landscape of solid tumors such as that of pancreatic and colorectal tumors requires the accumulation of many genetic events, a process that requires decades to complete. This timeline offers an incredible window of opportunity for the early detection, which is often associated with an excellent prognosis, of this disease.
The corresponding proteins were already known at that time to play a pivotal role in the signaling and proliferation of normal and cancerous cells.
Multiple members of the protein kinases family had already been linked to tumorigenesis.
Kinases are clearly amenable to pharmacologic inhibition, making them attractive drug targets.
The mutational analysis of all the tyrosine-kinase domains in colorectal cancers revealed that 30% of cases had a mutation in at least one tyrosine-kinase gene, and overall mutations were identified in eight different kinases, most of which had not previously been linked to cancer.13 An additional mutational analysis of the coding exons of 518 protein kinase genes in 210 diverse human cancers, including breast, lung, gastric, ovarian, renal, and acute lymphoblastic leukemia, identified approximately 120 mutated genes that probably contribute to oncogenesis.14 Because kinase activity is attenuated by enzymes that remove phosphate groups called phosphatases, the rational next step in these studies was to perform a mutation analysis of the protein tyrosine phosphatases. A mutational investigation of this family in colorectal cancer identified that 25% of cases had mutations in six different phosphatase genes (PTPRF, PTPRG, PTPRT, PTPN3, PTPN13, or PTPN14).16 A combined analysis of the protein tyrosine kinases and the protein tyrosine phosphatases showed that 50% of colorectal cancers had mutations in a tyrosine-kinase gene, a protein tyrosine phosphatase gene, or both, further emphasizing the pivotal role of protein phosphorylation in neoplastic progression. Many of the identified genes had previously been linked to human cancer, thus validating the unbiased comprehensive mutation profiling. These landmark studies led to additional gene family surveys.
The phosphatidylinositol 3-kinase (PI3K) gene family, which also plays a role in proliferation, adhesion, survival, and motility, was also comprehensively investigated.17 Sequencing of the exons encoding the kinase domain of all 16 members belonging to this family pinpointed PIK3CA as the only gene to harbor somatic mutations. When the entire coding region was analyzed, PIK3CA was found to be somatically mutated in 32% of colorectal cancers. At that time, the PIK3CA gene was certainly not a newcomer in the cancer arena, because it had previously been shown to be involved in cell transformation and metastasis.17 Strikingly, its staggeringly high mutation frequency was discovered only through systematic sequencing of the corresponding gene family.15 Subsequent analysis of PIK3CA in other tumor types identified somatic mutations in this gene in additional cancer types, including 36% of hepatocellular carcinomas, 36% of endometrial carcinomas, 25% of breast carcinomas, 15% of anaplastic oligodendrogliomas, 5% of medulloblastomas and anaplastic astrocytomas, and 27% of glioblastomas.18,19,20,21,22 It is known that PIK3CA is one of the two (the other being KRAS) most commonly mutated oncogenes in human cancers. Further investigation of the PI3K pathway in colorectal cancer showed that 40% of tumors had genetic alterations in one of the PI3K pathway genes, emphasizing the central role of this pathway in colorectal cancer pathogenesis.23
Although most cancer genome studies of large gene families have focused on the kinome, recent analyses have revealed that members of other families highly represented in the human genome are also a target of mutational events in cancer. This is the case of proteases, a complex group of enzymes consisting of at least 569 components that constitute the so-called human degradome.24 Proteases exhibit an elaborate interplay with kinases and have traditionally been associated with cancer progression because of their ability to degrade extracellular matrices, thus facilitating tumor invasion and metastasis.25,26 However, recent studies have shown that these enzymes hydrolyze a wide variety of substrates and influence many different steps of cancer, including early stages of tumor evolution.27 These functional studies have also revealed that beyond their initial recognition as prometastatic enzymes, they play dual roles in cancer, as assessed by the identification of a growing number of tumor-suppressive proteases.28
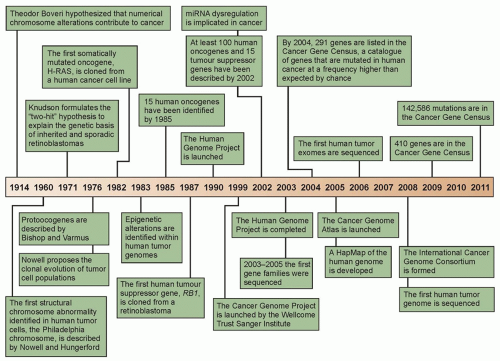
Figure 1.2 Timeline of seminal hypotheses, research discoveries, and research initiatives that have led to an improved understanding of the genetic etiology of human tumorigenesis within the past century. The consensus cancer gene data were obtained from the Wellcome Trust Sanger Institute Cancer Genome Project Web site (http://www.sanger.ac.uk/genetics/CGP). (Redrawn from Bell DW. Our changing view of the genomic landscape of cancer. J Pathol 2010;220:231-243.)
These findings emphasized the possibility that mutational activation or inactivation of protease genes occurs in cancer. A systematic analysis of genetic alterations in breast and colorectal cancers revealed that proteases from different catalytic classes were somatically mutated in cancer.29 These results prompted the mutational analysis of entire protease families such as matrix metalloproteinases (MMP), a disintegrin and metalloproteinase (ADAM), and ADAMs with thrombospondin domains (ADAMTS) in different tumors. These studies led to the identification of protease genes frequently mutated in cancer, such as MMP8, which is mutated and functionally inactivated in 6.3% of human melanomas.30,31
The mutational status of caspases has also been extensively analyzed in different tumors because these proteases play a fundamental role in the execution of apoptosis, one of the hallmarks of cancer.32 These studies demonstrated that CASP8 is deleted in neuroblastomas and inactivated by somatic mutations in a variety of human malignancies, including head and neck, colorectal, lung, and gastric carcinomas.33,34,35 Other large protease families whose components are often mutated in cancer are the deubiquitinating enzymes (DUB), which catalyze the removal of ubiquitin and ubiquitin-like modifiers of their target proteins.36 Some DUBs were initially identified as oncogenic proteins, but further work has shown that other deubiquitinases, such as CYLD, A20, and BAP1, are tumor suppressors inactivated in cancer. CYLD is mutated in patients with familial cylindromatosis, a disease characterized by the formation of multiple tumors of skin appendages.37 A20 is a DUB family member encoded by the TNFAIP3 gene, which is mutated in a large number of Hodgkin lymphomas and primary mediastinal B-cell lymphomas.38,39,40,41 Finally, the BAP1 gene, encoding an ubiquitin C-terminal hydrolase, is frequently mutated in metastasizing uveal melanomas42 and in other human malignancies, such as mesothelioma and renal cell carcinoma.43
Mutational Analysis of Exomes Using Sanger Sequencing
Although the gene family approach for the identification of cancer genes has proven extremely valuable, it still is a candidate approach and thus biased in its nature. The next step forward in the mutational profiling of cancer has been the sequencing of exomes, which is the entire coding portion of the human genome (18,000 proteinencoding genes). The exomes of many different tumors—including breast, colorectal, pancreatic, and ovarian clear cell carcinomas; glioblastoma multiforme; and medulloblastoma—have been analyzed using Sanger sequencing. For the first time, these large-scale analyses allowed researchers to describe and understand the genetic complexity of human cancers.29,44,45,46,47,48 The declared goals of these exome studies were to provide methods for exomewide mutational analyses in human tumors, to characterize their spectrum and quantity of somatic mutations, and, finally, to discover new genes involved in tumorigenesis as well as novel pathways that have a role in these tumors. In these studies, sequencing data were complemented with gene expression and copy number analyses, thus providing a comprehensive view of the genetic complexity of human tumors.45,46,47,48 A number of conclusions can be drawn from these analyses, including the following:
Cancer genomes have an average of 30 to 100 somatic alterations per tumor in coding regions, which was a higher number than previously thought. Although the alterations included point mutations, small insertions, deletions, or amplifications, the great majority of the mutations observed were single-base substitutions.45,46
Even within a single cancer type, there is a significant intertumor heterogeneity. This means that multiple mutational patterns (encompassing different mutant genes) are present in tumors that cannot be distinguished based on histologic analysis. The concept that individual tumors have a unique genetic milieu is highly relevant for personalized medicine, a concept that will be further discussed.
The spectrum and nucleotide contexts of mutations differ between different tumor types. For example, over 50% of mutations in colorectal cancer were C:G to T:A transitions, and 10% were C:G to G:C transversions. In contrast, in breast cancers, only 35% of the mutations were C:G to T:A transitions, and 29% were C:G to G:C transversions. Knowledge of mutation spectra is vital because it allows insight into the mechanisms underlying mutagenesis and repair in the various cancers investigated.
A considerably larger number of genes that had not been previously reported to be involved in cancer were found to play a role in the disease.
Solid tumors arising in children, such as medulloblastomas, harbor on average 5 to 10 times less gene alterations compared to a typical adult solid tumor. These pediatric tumors also harbor fewer amplifications and homozygous deletions within coding genes compared to adult solid tumors.
Importantly, to deal with the large amount of data generated in these genomic projects, it was necessary to develop new statistical and bioinformatic tools. Furthermore, an examination of the overall distribution of the identified mutations allowed for the development of a novel view of cancer genome landscapes and a novel definition of cancer genes. These new concepts in the understanding of cancer genetics are further discussed in the following paragraphs. The compiled conclusions derived from these analyses have led to a paradigm shift in the understanding of cancer genetics.
A clear indication of the power of the unbiased nature of the whole exome surveys was revealed by the discovery of recurrent mutations in the active site of IDH1, a gene with no known link to gliomas, in 12% of tumors analyzed.46 Because malignant gliomas are the most common and lethal tumors of the central nervous system, and because glioblastoma multiforme (GBM; World Health Organization grade IV astrocytoma) is the most biologically aggressive subtype, the unveiling of IDH1 as a novel GBM gene is extremely significant. Importantly, mutations of IDH1 predominantly occurred in younger patients and were associated with a better prognosis.49 Follow-up studies showed that mutations of IDH1 occur early in glioma progression; the R132 somatic mutation is harbored by the majority (greater than 70%) of grades II and III astrocytomas and oligodendrogliomas, as well as in secondary GBMs that develop from these lower grade lesions.49,50,51,52,53,54,55 In contrast, less than 10% of primary GBMs harbor these alterations. Furthermore, analysis of the associated IDH2 revealed recurrent somatic mutations in the R172 residue, which is the exact analog of the frequently mutated R132 residue of IDH1. These mutations occur mostly in a mutually exclusive manner with IDH1 mutations,49,51 suggesting that they have equivalent phenotypic effects. Subsequently, IDH1 mutations have been reported in additional cancer types, including hematologic neoplasias.56,57,58
Next-Generation Sequencing and Cancer Genome Analysis
In 1977, the introduction of the Sanger method for DNA sequencing with chain-terminating inhibitors transformed biomedical research.8 Over the past 30 years, this first-generation technology has been universally used for elucidating the nucleotide sequence of DNA molecules. However, the launching of new large-scale projects, including those implicating whole-genome sequencing of cancer samples, has made necessary the development of new methods that are widely known as next-generation sequencing technologies.59,60,61 These approaches have significantly lowered the cost and the time required to determine the sequence of the 3 × 109 nucleotides present in the human genome. Moreover, they have a series of advantages over Sanger sequencing, which are of special interest for the analysis of cancer genomes.62 First, next-generation sequencing approaches are more sensitive than Sanger methods and can detect somatic mutations even when they are present in only a subset of tumor cells.63 Moreover, these new sequencing strategies are quantitative and can be used to simultaneously determine both nucleotide sequence and copy number variations.64 They can also be coupled to other procedures such as those involving paired-end reads, allowing for the identification of multiple structural alterations, such as insertions, deletions, and rearrangements, that commonly occur in cancer genomes.63 Nonetheless, next-generation sequencing still presents some limitations that are mainly derived from the relatively high error rate in the short reads generated during the sequencing process. In addition, these short reads make the task of de novo assembly of the generated sequences and the mapping of the reads to a reference genome extremely complex. To overcome some of these current limitations, deep coverage of each analyzed genome is required and a careful validation of the identified variants must be performed, typically using Sanger sequencing. As a consequence, there is a substantial increase in both the cost of the process and in the time of analysis. Therefore, it can be concluded that whole-genome sequencing of cancer samples is already a feasible task, but not yet a routine process. Further technical improvements will be required before the task of decoding the entire genome of any malignant tumor of any cancer patient can be applied to clinical practice.
The number of next-generation sequencing platforms has substantially grown over the past few years and currently includes technologies from Roche/454, Illumina/Solexa, Life/APG’s SOLiD3, Helicos BioSciences/HeliScope, and Pacific Biosciences/PacBio RS.61 Noteworthy also are the recent introduction of the Polonator G.007 instrument, an open source platform with freely available software and protocols; the Ion Torrent’s semiconductor sequencer; as well as those involving self-assembling DNA nanoballs or nanopore technologies.65,66,67 These new machines are driving the field toward the era of third-generation sequencing, which brings enormous clinical interest because it can substantially increase the speed and accuracy of analyses at reduced costs and can facilitate the possibility of single-molecule sequencing of human genomes. A comparison of next-generation sequencing platforms is shown in Table 1.1. These various platforms differ in the method utilized for template preparation and in the nucleotide sequencing and imaging strategy, which finally result in their different performance. Ultimately, the most suitable approach depends on the specific genome sequencing projects.61
Current methods of template preparation first involve randomly shearing genomic DNA into smaller fragments, from which a library of either fragment templates or mate-pair templates are generated. Then, clonally amplified templates from single DNA molecules are prepared by either emulsion polymerase chain reaction (PCR) or solid-phase amplification.68,69 Alternatively, it is possible to prepare single-molecule templates through methods that require less starting material and that do not involve PCR amplification reactions, which can be the source of artifactual mutations.70 Once prepared, templates are attached to a solid surface in spatially separated sites, allowing thousands to billions of nucleotide sequencing reactions to be performed simultaneously.
TABLE 1.1 Comparative Analysis of Next-Generation Sequencing Platforms
Platform
Library/Template Preparation
Sequencing Method
Average Read-Length (Bases)
Run Time (Days)
Gb Per Run
Instrument Cost (U.S.$)
Comments
Roche 454 GS FLX
Fragment, mate-pair Emulsion PCR
Pyrosequencing
400
0.35
0.45
500,000
Fast run times High reagent cost
Illumina HiSeq 2000
Fragment, mate-pair Solid phase
Reversible terminator
100-125
8 (mate-pair run)
150-200
540,000
Most widely used platform
Low multiplexing capability
Life/APG’s SOLiD 5500xl
Fragment, mate-pair Emulsion PCR
Cleavable probe, sequencing by ligation
35-75
7 (mate-pair run)
180-300
595,000
Inherent error correction
Long run times
Helicos BioSciences HeliScope
Fragment, mate-pair Single molecule
Reversible terminator
32
8 (fragment run)
37
999,000
Nonbias template representation
Expensive, high error rates
Pacific Biosciences PacBio RS
Fragment Single molecule
Real-time sequencing
1,000
1
0.075
NA
Greatest potential for long reads
Highest error rates
Polonator G.007
Mate pair Emulsion PCR
Noncleavable probe, sequencing by ligation
26
5 (mate-pair run)
12
170,000
Least expensive platform
Shortest read lengths
NA, not available.
Data represent an update of information provided in Metzker ML. Sequencing technologies—the next generation. Nat Rev Genet 2010;11:31-46.
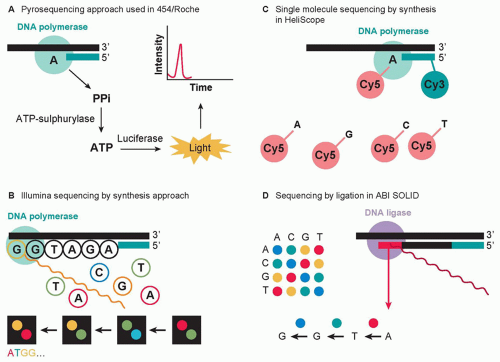
The sequencing methods currently used by the different next-generation sequencing platforms are diverse and have been classified into four groups: cyclic reversible termination, singlenucleotide addition, real-time sequencing, and sequencing by ligation (Fig. 1.3).61,71 These sequencing strategies are coupled with different imaging methods, including those based on measuring bioluminescent signals or involving four-color imaging of single molecular events. Finally, the extraordinary amount of data released from these nucleotide sequencing platforms is stored, assembled, and analyzed using powerful bioinformatic tools that have been developed in parallel with next-generation sequencing technologies.72
Next-generation sequencing approaches represent the newest entry into the cancer genome decoding arena and have already been applied to cancer analyses. The first research group to apply these methodologies to whole cancer genomes was that of Ley et al.,73 who reported in 2008 the sequencing of the entire genome of a patient with acute myeloid leukemia (AML) and its comparison with the normal tissue from the same patient, using the Illumina/Solexa platform. As further described, this work allowed for the identification of point mutations and structural alterations of putative oncogenic relevance in AML and represented proof of principle of the relevance of next-generation sequencing for cancer research.
The sequence of the first whole cancer genome was reported in 2008, where AML and normal skin from the same patient were described.73 Numerous additional whole genomes, together with the corresponding normal genomes of patients with a variety of malignant tumors, have been reported since then.56,63,74,75,76,77,78,79,80,81,82,83,84,85,86
The first available whole genome of a cytogenetically normal AML subtype M1 (AML-M1) revealed eight genes with novel mutations along with another 500 to 1,000 additional mutations found in noncoding regions of the genome. Most of the identified genes had not been previously associated with cancer. However, validation of the detected mutations did not identify novel recurring mutations in AML.73 Concomitantly, with the expansion in the use of next-generation sequencers, many other whole genomes from a number of cancer types started to be evaluated in a similar manner (Fig. 1.4).87
In contrast to the first AML whole genome, the second did observe a recurrent mutation in IDH1, encoding isocitrate dehydrogenase.56 Follow-up studies extended this finding and reported that mutations in IDH1 and the related gene IDH2 occur at a 20% to 30% frequency in AML patients and are associated with a poor prognosis in some subgroups of patients.79,80,88 A good example illustrating the high pace at which second-generation technologies and their accompanying analytical tools are found is demonstrated by the following finding derived from a reanalysis of the first AML whole genome. Thus, when improvements in sequencing techniques were available, the first AML whole genome (described previously), which identified no recurring mutations and had a 91.2% diploid coverage, was reevaluated by deeper sequence coverage, yielding 99.6% diploid coverage of the genome. This improvement, together with more advanced mutation calling algorithms, allowed for the discovery of several nonsynonymous mutations that had not been identified in the initial sequencing. This included a frameshift mutation in the DNA methyltransferase gene DNMT3A. Validation of DNMT3A in 280 additional de novo AML patients to define recurring mutations led to the significant discovery that a total of 22.1% of AML cases had mutations in DNMT3A that were predicted to affect translation. The median overall survival among patients with DNMT3A mutations was significantly shorter than that among patients without such mutations (12.3 months versus 41.1 months; p <0.001).
Figure 1.3 Advances in sequencing chemistry implemented in next-generation sequencers. (A) The pyrosequencing approach implemented in 454/Roche sequencing technology detects incorporated nucleotides by chemiluminescence resulting from PPi release. (B) The Illumina method utilizes sequencing by synthesis in the presence of fluorescently labeled nucleotide analogs that serve as reversible reaction terminators. (C) The singlemolecule sequencing by synthesis approach detects template extension using Cy3 and Cy5 labels attached to the sequencing primer and the incoming nucleotides, respectively. (D) The SOLiD method sequences templates by sequential ligation of labeled degenerate probes. Two-base encoding implemented in the SOLiD instrument allows for probing each nucleotide position twice. (From Morozova O, Hirst M, Marra MA. Applications of new sequencing technologies for transcriptome analysis. Annu Rev Genomics Hum Genet 2009;10:135-151.)
Shortly after this study, complete sequences of a series of cancer genomes, together with matched normal genomes of the same patients, were reported.56,78,83,84 These works opened the way to more ambitious initiatives, including those involving large international consortia, aimed at decoding the genome of malignant tumors from thousands of cancer patients. Thus, over the last 2 years, many whole genomes of different human malignancies have been made available.74,75,76
In addition to direct applications of next-generation sequencing technologies for the mutational analysis of cancer genomes, these methods have an additional range of applications in cancer research. Thus, genome sequencing efforts have begun to elucidate the genomic changes that accompany metastasis evolution through a comparative analysis of primary and metastatic lesions from breast and pancreatic cancer patients.77,81,82,85 Likewise, massively parallel sequencing has been used to analyze the evolution of a tongue adenocarcinoma in response to selection by targeted kinase inhibitors.89 Detailed information of several of these whole genome projects is found in the following paragraph.
The first solid cancer to undergo whole-genome sequencing was a malignant melanoma that was compared to a lymphoblastoid cell line from the same individual.83 Impressively, a total of 33,345 somatic base substitutions were identified, with 187 nonsynonymous substitutions in protein-coding sequences, at least one order of magnitude higher than any other cancer type. Most somatic base substitutions were C:G > T:A transitions, and of the 510 dinucleotide substitutions, 360 were CC.TT/GG.AA changes, which is consistent with ultraviolet light exposure mutation signatures previously reported in melanoma.14 Such results from the most comprehensive catalog of somatic mutations not only provide insight into the DNA damage signature in this cancer type, but can also be useful in determining the relative order of some acquired mutations. Indeed, this study shows that a significant correlation exists between the presence of a higher proportion of C.A/G.T transitions in early (82%) compared to late mutations (53%). Another important aspect that the comprehensive nature of this melanoma study provided was that cancer mutations are spread out unevenly throughout the genome, with a lower prevalence in regions of transcribed genes, suggesting that DNA repair occurs mainly in these areas.
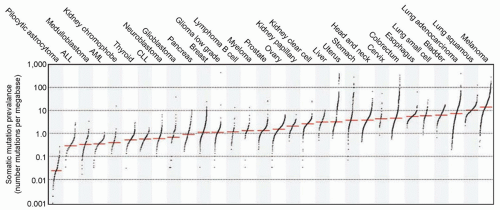
Figure 1.4 The prevalence of somatic mutations across human cancer types. Every dot represents a sample, whereas the red horizontal lines are the median numbers of mutations in the respective cancer types. The vertical axis (log scaled) shows the number of mutations per megabase, whereas the different cancer types are ordered on the horizontal axis based on their median numbers of somatic mutations. ALL, acute lymphoblastic leukemia; AML, acute myeloid leukemia; CLL, chronic lymphocytic leukemia. (Used with permission from Alexandrov LB, Nik-Zainal S, Wedge DC, et al. Signatures of mutational processes in human cancer. Nature 2013;500:415-421.)
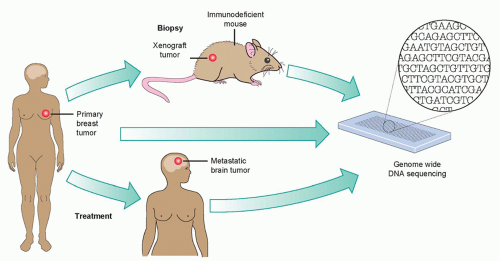
Figure 1.5 Covering all the bases in metastatic assessment. Ding et al.85 performed a genomewide analysis on three tumor samples: a patient’s primary breast tumor; her metastatic brain tumor, which formed despite therapy; and a xenograft tumor in a mouse, originating from the patient’s breast tumor. They find that the primary tumor differs from the metastatic and xenograft tumors mainly in the prevalence of genomic mutations. (With permission from Gray J. Cancer: genomics of metastasis. Nature 2010;464:989-990.)
An interesting and pioneering example of the power of wholegenome sequencing in deciphering the mutation evolution in carcinogenesis was seen in a study in which a basallike breast cancer tumor, a brain metastasis, a tumor xenograft derived from the primary tumor, and the peripheral blood from the same patient were compared (Fig. 1.5).85 This analysis showed a wide range of mutant allele frequencies in the primary tumor, which was narrowed in the metastasis and xenograft samples. This suggested that the primary tumor was significantly more heterogeneous in its cell populations compared to its matched metastasis and xenograft samples because these underwent selection processes whether during metastasis or transplantation. The clear overlap in mutation incidence between the metastatic and xenograft cases suggests that xenografts undergo similar selection as metastatic lesions and, therefore, are a reliable source for genomic analyses. The main conclusion of this whole-genome study was that, although metastatic tumors harbor an increased number of genetic alterations, the majority of the alterations found in the primary tumor are preserved. Interestingly, single-cell genome sequencing of a breast primary tumour and its liver metastasis indicated that a single clonal expansion formed the primary tumor and seeded the metastasis.90 Further studies have confirmed and extended these findings to metastatic tumors from different types, including renal and pancreatic carcinomas.91
The importance of performing whole-genome sequencing has also been emphasized by the recent identification of somatic mutations in regulatory regions, which can also elicit tumorigenesis. In a study reviewing the noncoding mutations in 19 melanoma whole-genome samples, two recurrent mutations in 17 of the 19 cases studied within the telomerase reverse transcriptase (TERT) promoter region were revealed.92 When these two mutations were investigated in an extension of 51 additional tumors and their matched normal tissues, it was observed that 33 tumors harbored one of the mutations and that the mutations occurred in a mutually exclusive manner. These two mutations generate an identical 11 bp nucleotide stretch that contains the consensus binding site for E-twenty-six (ETS) transcription factors. When cloned into a luciferase reporter assay system, it was shown that these mutations conferred a two- to fourfold increase in transcriptional activity of this promoter in five melanoma cell lines. Although this alteration is much more frequent in melanoma, it is also present in other cancer types because 16% of the cancers listed in the Cancer Cell Line Encyclopedia harbor one of the two TERT mutations. In combination, these TERT mutations are seen in a greater frequency than BRAF- and NRAS-activating mutations. They occur in a mutually exclusive manner and in regions that do not show a large background mutation rate, all suggesting that these mutations are important driver events contributing to oncogenesis. Further supporting this was another recent study that identified these same two mutations in the germ line of familial melanoma patients.93
As the TERT promoter mutation discovery shows, regions of the genome that do not code for proteins are just as vital in our understanding of the biology behind tumor development and progression. Another class of non-protein-coding regions in the genome are the noncoding RNAs. One class of noncoding RNAs are microRNAs (miRNA). Discovered 20 years ago, miRNAs are known to be expressed in a tissue or developmentally specific manner and their expression can influence cellular growth and differentiation along with cancer-related pathways such as apoptosis or stress response. miRNAs do this through either overexpression, leading to the targeting and downregulation of tumor suppressor genes, or inversely through their own downregulation, leading to increased expression of their target oncogene. miRNAs have been extensively studied in cancer and their functional effects have been noted in a wide variety of cancers like glioma94 and breast cancer,95 to name just a few.
Another class of noncoding RNAs (ncRNA) are the long noncoding RNAs (lncRNA). These RNAs are typically greater than 200 bp and can range up to 100 kb in size. They are transcribed by RNA polymerase II and can undergo splicing and polyadenylation. Although much less extensively studied when compared to miRNAs for their role in cancer, lncRNAs are beginning to come under much more scrutiny. A recent study of the steroid receptor RNA activator (SRA) revealed two transcripts, a lncRNA (SRA) and a translated transcript (steroid receptor RNA activator protein [SRAP]), that coexist within breast cancer cells. However, their expression varies within breast cancer cell lines with different phenotypes. It was shown that in a more invasive breast cancer line, higher relative levels of the noncoding transcript were seen.96 Because this ncRNA acts as part of a ribonucleoprotein complex that is recruited to the promoter region of regulatory genes, it has been hypothesized that this shift in balance between both noncoding and coding transcripts may be associated with growth advantages. When this balance was shifted in vitro, it led to a large increase in transcripts associated with invasion and migration. The results of this study highlight the importance of the investigation into the roles of ncRNA in tumor development or progression and confirm again that the study of coding variants is not sufficient in determining the full genomic spectrum of cancer.
Only gold members can continue reading. Log In or Register to continue