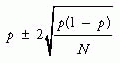Clinical decisions are based on the weight of evidence bearing on a question. Sometimes the results of large, strong studies are so compelling that they eclipse all other studies of the same question. More often, however, clinicians depend on the accumulation of evidence from many less definitive studies. When considering these individual studies, clinicians need to establish the context for that one piece of evidence by asking, “Have there been other good studies of the same question, what have they shown, and do their results establish a pattern when the studies’ scientific strengths and statistical precision are taken into account?” Reviews are intended to answer these kinds of questions.
Reviews are made available to users in many different forms. They may be articles in journals, chapters in textbooks, summaries prepared by the Cochrane Collaboration, or monographs published by professional or governmental organizations. If the authors of individual research articles are doing their job properly, they will provide information about results of previous studies in the Introduction or Discussion sections of the article.
However a review is made available, the important issue is how well it is done. There are many different ways, each with strengths and weaknesses. In this chapter, we briefly describe traditional reviews and then address in more detail a powerful and more explicitly scientific approach called “systematic reviews.”
TRADITIONAL REVIEWS
In traditional reviews, called narrative reviews, an
expert in the field summarizes evidence and makes recommendations. An advantage of these reviews is that they can address broad-gauged topics, such as “management of the diabetic patient,” and consider a range of issues, such as diagnostic criteria, blood glucose control and monitoring, cardiovascular risk
factor modification, and micro- and macrovascular complications. Compliance and cost-effectiveness may also be included. Clinicians need guidance on such a broad range of questions and experts are in a good position to provide it. Authors usually have experience with the disease, know the pertinent evidence base, and have been applying their knowledge in the care of patients.
A disadvantage of narrative reviews is that evidence and recommendations in them may be colored by value judgments that are not made explicit. The lack of structure of traditional reviews may hide important threats to validity. Original research might be cited without a clear account of how articles were found, raising the danger that they were selectively cited to support a point of view. Personal experience and conventional wisdom are often included and may be difficult to distinguish from bedrock research evidence. The strength of the original research may not be carefully critiqued, but instead suggested by shorthand indicators of quality—such as the prestige of the journal, eminence of the author, how recently the study was published, the number of articles for and against a given conclusion, and perhaps general research design (e.g., as randomized trial)—without regard for how well studies were actually designed and executed. Also, there may be no explicit rationale for why one research finding was valued over another.
Of course, a traditional review may not have these limitations, especially if it has been peer reviewed by other experts with complementary expertise and if the author has included evidence from more structured reviews. However, concern about the limitations of traditional reviews, especially lack of structure and transparency, has prompted a new approach.
SYSTEMATIC REVIEWS
Systematic reviews are rigorous reviews of the evidence bearing on specific clinical questions. They are “systematic” because they summarize original research following a scientifically based plan that has been decided on in advance and made explicit at every step. As a result, readers can see the strength of the evidence for whatever conclusions are reached and, in principle, check the validity for themselves. Sometimes it is possible to combine studies, giving a more precise estimate of effect size than is available in individual studies.
Systematic reviews are especially useful for addressing a single, focused question such as whether angiotensin-converting enzyme inhibitors reduce the death rate in patients with congestive heart failure or whether skin adhesives are better than sutures for closing superficial lacerations. For a systematic review to be useful, strong studies of the question should be available. There should not be so few studies of the question that one could just as well critique the individual studies directly. The study results should disagree or at least leave the question open; if all the studies agree with one another, there is nothing to reconcile in a review. Systematic reviews are also useful when there is reason to believe that politics, intellectual passion, or self-interest are accounting for how research results are being interpreted.
Systematic reviews can provide a credible answer to targeted (but not broad-gauged) questions and offers a set of possibilities for how traditional reviews can be done better. They complement, but cannot replace, traditional reviews. Systematic reviews are most often used to summarize randomized controlled trials; therefore, we will base our comments on trials. However, the same methods are used to summarize observational studies of risk and studies of diagnostic test performance.
The elements of a systematic review are summarized in
Table 13.1 and will be addressed one at a time throughout the remainder of this chapter.
Finding All Relevant Studies
The first step in a systematic review is to find all the studies that bear on the question at hand. The review should include a complete sample of the best studies of the question, not just a biased sample of studies that happen to have come to attention. Clinicians who review topics less formally—for colleagues in rounds, morning report, and journal clubs—face a similar challenge and should use similar methods, although the process cannot be as exhaustive.
How can a reviewer be reasonably sure that he or she has found all the best studies, considering that the medical literature is vast and widely dispersed? No one method of searching is sufficient for this task, so multiple complementary approaches are used (
Table 13.2).
Most reviews start by searching online databases of published research, among them MEDLINE, (the National Library of Medicine’s electronic database of published articles) EMBASE, and the Cochrane Database of Systematic Reviews. There are many others that can be identified with a librarian’s help. Some, such as MEDLINE, can be searched both for a content area (such as treatment of atrial fibrillation) and for a quality marker (e.g., randomized controlled trial). However, even in the best hands the sensitivity of MEDLINE searches (even for articles that are in MEDLINE) is far from perfect. Also, the contents of the various databases tend to complement each other. Therefore, database searching is useful but not sufficient.
Other ways of finding the right articles make up for what database searches might have missed. Recent reviews and textbooks (particularly electronic textbooks that are continually updated) are a source. Experts in the content area (e.g., rheumatic heart disease or Salmonella infection) may recommend studies that were not turned up by the other approaches. References cited in articles already found are another possibility. There are a growing number of registries of clinical trials and funded research that can be used to find unpublished results.
The goal of consulting all these sources is to avoid missing any important article, even at the expense of inefficiency. In diagnostic test terms, the reviewer uses multiple parallel tests to increase the sensitivity of the search, even at the expense of many false-positive results (i.e., unwanted or redundant citations), which need to be weeded out by examining the studies themselves.
In addition to exercising due diligence in finding articles, authors of systematic reviews explicitly describe the search strategy for their review, including search terms. This allows readers to see the extent to which the reviewer took into account all the studies that were available at the time.
Limit Reviews to Scientifically Strong, Clinically Relevant Studies
To be included in a systematic review, studies must meet a threshold for scientific strength. The assumption is that only the relatively strong studies should count. How is that threshold established? Various expert groups have proposed criteria for adequate scientific strength, and their advantages and limitations are discussed later in this chapter.
Usually only a small proportion of studies are selected from a vast number of potential articles on the topic. Many articles describe the biology of disease and are not ready for clinical application. Others communicate opinions or summaries of existing evidence, not original clinical research. Many studies are not scientifically strong, and the information they contain is eclipsed by stronger studies. Relatively few articles report evidence bearing directly on the clinical question and are both scientifically strong and clinically relevant.
Table 13.3 shows how articles were selected for a systematic review of statin drugs for the prevention of infections; only 11 of 632 publications identified were included in the review.
Are Published Studies a Biased Sample of All Completed Research?
The articles cited in systematic reviews should include all scientifically strong studies of the question, regardless of whether have been published.
Publication bias is the tendency for published studies to be
systematically different from all completed studies of a question. In general, published studies are more likely to be “positive” (i.e., to find an effect) for several reasons, related to a general preference for positive results. Investigators are less likely to complete studies that seem likely to end up negative and less likely to submit negative studies to journals. Journal peer reviewers are less likely to find negative studies interesting news, and editors are less likely to publish them.
Other selective pressures may favor positive studies. Authors may report outcomes that were not identified or made primary before data were collected and were selected for emphasis in publications after the results were available.
To get around these problems, some authors of systematic reviews make a concerted effort to find unpublished studies, including those that were funded and begun but not completed. They are aided in this effort by public registries of all studies that have been started.
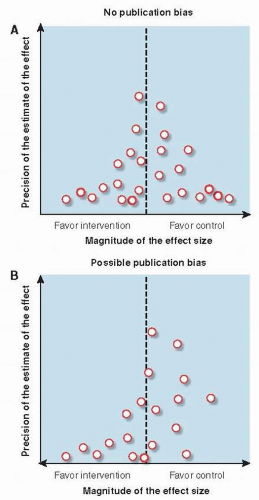
Funnel plots are a graphical way of detecting bias in the selection of studies for systematic reviews. For each study, the effect size is plotted against some measure of the study’s size or precision, such as sample size, number of outcome events, or confidence interval (
Fig. 13.1).
In the absence of publication bias (
Fig. 13.1A), large trials (plotted at the top of the figure) are likely to be published no matter what they find and yield estimates of comparative effectiveness that are closely grouped around the true effect size. Small studies (plotted in the lower part of the figure) are more likely to vary in reported effect size because of statistical imprecision, and so to be spread out at the bottom of the figure, surrounding the true effect size. In the absence of publication bias, they would be as often in the lower right as the lower left of the figure. The result, in the absence of bias, is a symmetrical, peaked distribution—an inverted funnel. Publication bias, particularly the tendency for small studies to be published only if they are positive, shows up as asymmetry in the funnel plot (
Fig. 13.1B). There are disproportionately fewer small studies that favor the control group, seen as a paucity of studies in the lower right corner of the figure.
Other factors, not directly related to distaste for negative studies, can cause publication bias. Funding of research by agencies with a financial interest in the results can also lead to distortions in the scientific record. Outcomes of studies sponsored by industry (usually drug and device companies) are more likely to favor the sponsor’s product than those with other funding sources. One possible reason is that industry sponsors sometimes require, as a condition of funding research, that they approve the resulting articles before they are submitted to journals. Industry sponsors have blocked publication of research they have funded that has not, in their opinion, found the “right” result.
How Good Are the Best Studies?
Clinicians need to know just how good the best studies of a question are so that they will know how seriously to take the conclusions of the systematic review. Are the studies so strong that it would be irresponsible to discount them? Or are they weak, suggesting that it is reasonable to not follow their lead?
Many studies have shown that the individual elements of quality discussed throughout this book, such as concealment of treatment assignment, blinding, follow-up, and sample size, are systematically related to study results. The quality of the evidence identified by the systematic review can be summarized by a table showing the extent to which markers of quality are present in the studies included in the review.
Individual measures of quality can also be combined into summary measures. A simple, commonly used scale for studies of treatment effectiveness, the Jadad Scale, includes whether the study was described as randomized and double-blinded and whether there was a description of withdrawals and dropouts (
3). However, there is not a clear relationship between summary scores for study quality and results (
4). Why might this be? The component studies in systematic reviews are already highly selected and, therefore, might not differ much from one another in quality. Also, summary measures of quality typically add up scores for the presence or absence of each element of quality, and there is no reason to believe that each makes an equal contribution to the overall validity of the study. It is not difficult to imagine, for example, that weakness in one aspect of a study might be so damaging as to render the entire study invalid, even though all the other aspects of quality are exemplary.