Risk: From Disease to Exposure
“… take two groups presumed to be representative of persons who do and do not have the disease and determine the percentage of each group who have the characteristic…. This yields, not a true rate, but rather what is usually referred to as a relative frequency.”
—Jerome Cornfield 1952
KEY WORDS
Latency period
Case-control study
Control
Population-based case-control study
Nested case-control study
Matching
Umbrella matching
Overmatching
Recall bias
Odds ratio
Estimated relative risk
Prevalence odds ratio
Crude odds ratio
Adjusted odds ratio
Epidemic curve
Cohort studies are a wonderfully logical and direct way of studying risk, but they have practical limitations. Most chronic diseases take a long time to develop. The latency period, the period of time between exposure to a risk factor and the expression of its pathologic effects, is measured in decades for most chronic diseases. For example, smoking precedes coronary disease, lung cancer, and chronic bronchitis by 20 years or more, and osteoporosis with fractures occurs in the elderly because of diet and exercise patterns throughout life. Also, relatively few people in a cohort develop the outcome of interest, even though it is necessary to measure exposure in, and to follow-up, all members of the cohort. The result is that cohort studies of risk require a lot of time and effort, not to mention money, to get an answer. The inefficiency is especially limiting for very rare diseases.
Some of these limitations can be overcome by modifications of cohort methods, such as retrospective cohort or case-cohort designs, described in the preceding chapter. This chapter describes another way of studying the relationship between a potential risk (or protective) factor and disease more efficiently: case-control studies. This approach has two main advantages over cohort studies. First, it bypasses the need to collect data on a large number of people, most of whom do not get the disease and so contribute little to the results. Second, it is faster because it is not necessary to wait from measurement of exposure until effects occur.
But efficiency and timeliness come at a cost: Managing bias is a more difficult and sometimes uncertain task in case-control studies. In addition, these studies produce only an estimate of relative risk and no direct information on other measures of effect such as absolute risk, attributable risk, and population risks, all described in the Chapter 5.
The respective advantages and disadvantages of cohort and case-control studies are summarized in Table 6.1.
Despite the drawbacks of case-control studies, the trade-off between scientific strength and feasibility is often worthwhile. Indeed, case-control studies are indispensable for studying risk for very uncommon diseases, as shown in the following example.
Table 6.1 Summary of Characteristics of Cohort and Case-Control Studies | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Example
In the mid 2000s, clinicians began reporting cases of an unusual form of femoral fracture in women. Bisphosphonates, drugs taken to prevent osteoporosis, were suspected because they had been introduced in the decades before and act by reducing bone remodeling. Case series reported an association between bisphosphonates and atypical fractures, but the women in these studies took other drugs and had other diseases that could also have been related to their risk of fractures. To provide a more definitive answer to whether bisphosphonates were independently associated with atypical fractures, investigators in Sweden did a case-control study (1). From the National Swedish Patient Register, they identified all 59 women age 55 years or older with atypical femoral fractures in 2008. They also identified 263 controls, women in the same registry who had had ordinary femoral fractures (to match for underlying vulnerability to fractures). Other variables that might be related to both bisphosphonate use and atypical fractures were recorded, including age, use of bone-modifying drugs such as corticosteroids or estrogens, and diseases such as osteoporosis and previous fractures. After taking these other factors into account, women taking bisphosphonates were 33 times more likely to develop atypical fractures.
By adding a comparison group and accounting for other variables that might be related to bisphosphonate use and atypical fractures, the investigators were able to take the inference that bisphosphonates might be a cause of atypical fractures well beyond what was possible with case series alone.
This chapter, the third about risk, is titled “From Disease to Exposure” because case-control studies involve looking backward from disease to exposure, in contrast to cohort studies, which look forward from exposure to disease.
CASE-CONTROL STUDIES
The basic design of a case-control study is diagrammed in Figure 6.1. Two samples are selected: patients who have developed the disease in question and an otherwise similar group of people who have not developed the disease. The researchers then look back in time to measure the frequency of exposure to a possible risk factor in the two groups. The resulting data can be used to estimate the relative risk of disease related to a risk factor.
Example
Head injuries are relatively common among alpine skiers and snowboarders. It seems plausible that helmets would prevent these injuries, but critics point out that helmets might also increase head injuries by reducing field of vision, impairing hearing, and giving athletes a false sense of security. To obtain more definitive evidence of helmets’ actual effects, investigators in Norway did a case-control study (Fig. 6.2) (2). Cases and controls were chosen from visitors to eight major Norwegian alpine ski resorts during the 2002 winter season. Cases were all 578 people with head injuries reported by the ski patrol. Controls were a sample of people waiting in line at the bottom of the main ski lift at each of the eight resorts. For both cases and controls, investigators recorded other factors that might confound the relationship between helmet use and head injury, including age, sex, nationality, type of equipment, previous ski school attendance, rented or owned equipment, and skiing ability. After taking confounders into account, helmet use was associated with a 60% reduction in risk of head injury.
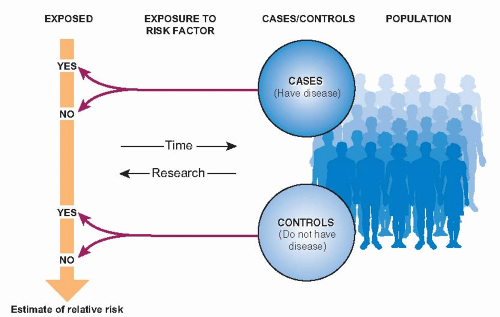 Figure 6.1 ▪ Design of case-control studies. |
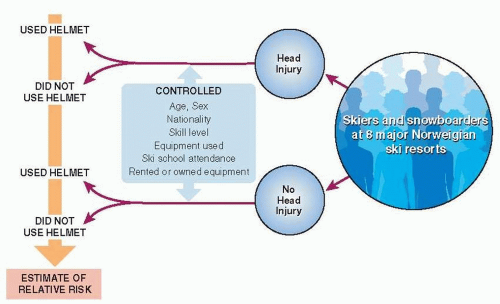 Figure 6.2 ▪ A case-control study of helmet use and head injuries among skiers and snowboarders. (Summary of Sulheim S, Holme I, Ekeland A, et al. Helmet use and risk of head injuries in alpine skiers and snowboarders. JAMA 2006;295:919-924.) |
The word control comes up in other situations, too. It is used in experimental studies to refer to people, animals, or biologic materials that have not been exposed to the study intervention. In diagnostic laboratories, “controls” refer to specimens that have a known amount of the material being tested for. As a verb, control is used to describe the process of taking into account, neutralizing, or subtracting the effects of variables that are extraneous to the main research question. Here, the term is used in the context of case-control studies to refer to people who do not have the disease or outcome under study.
DESIGN OF CASE-CONTROL STUDIES
The validity of case-control studies depends on the care with which cases and controls are selected, how well exposure is measured, and how completely potentially confounding variables are controlled.
Selecting Cases
The cases in case-control research should be new (incident) cases, not existing (prevalent) ones. The reasons are based on the concepts discussed in Chapter 2. The prevalence of a disease at a point in time is a function of both the incidence and duration of that disease. Duration is in turn determined by the rate at which patients leave the disease state (because of recovery or death) or persist in it (because of a slow course or successful palliation). It follows from these relationships that risk factors for prevalent disease may be risk factors for incidence, duration, or both; the relative contributions of the two cannot be determined. For example, if prevalent cases were studied, an exposure that caused a rapidly lethal form of the disease would result in fewer cases that were exposed, reducing relative risk and thereby suggesting that exposure is less harmful than it really is or even that it is protective.
At best, a case-control study should include all the cases or a representative sample of all cases that arise in a defined population. For example, the bisphosphonates study included all residents of Sweden in 2008 and the helmets study all skiers and snowboarders in eight major resorts in Norway (accounting for 55% of all ski runs in the country).
Some case-control studies, especially older ones, have identified cases in hospitals and referral centers where uncommon diseases are most likely to be found. This way of choosing cases is convenient, but it raises validity problems. These centers may attract particularly severe or atypical cases or those with unusual exposures—the wrong sample if the underlying research question in case-control studies is about ordinary occurrences of disease and exposures.
Also, it is difficult in this situation to be confident that controls, however they are chosen, are truly similar to cases in all ways other than exposure, which is critical to the validity of this kind of study (see the Selecting Controls section). Fortunately, it is rarely necessary to take this scientific risk because there are many databases that make true population sampling possible.
However the cases might be identified, it should be possible for both them and controls to be exposed to the risk factor and to experience the outcome. For example, in a case-control study of exercise and sudden death, cases and control would have to be equally able to exercise (if they chose to) to be eligible.
It goes without saying that diagnosis should be rigorously confirmed for cases (and excluded for controls), and the criteria made explicit. In the bisphosphonates study, investigators agreed on explicit criteria for atypical fractures of the femur and reviewed all radiographs, not just reports of them, to classify fracture type. One investigator then reviewed a random sample of radiographs for a second time without knowing how each had been classified, and there was complete agreement between the original and the second classifications.
Selecting Controls
Above all, the validity of case-control studies depends on the comparability of cases and controls. To be comparable, cases and controls should be members of the same base population and have an equal opportunity of being exposed. The best approach to meeting these requirements is to ensure that controls are a random sample of all non-cases in the same population or cohort that produced the cases.
The Population Approach
Studies in which cases and controls are a complete or random sample of a defined population are called population-based case-control studies. In practice, most of these populations are dynamic—that is, continually changing, with people moving in and out of the population—as described in Chapter 2 (3). This might bias the result, especially if cases and controls are sampled over a long period of time and exposure is changing rapidly during this time. This concern can be laid to rest if there is evidence that population turnover is in fact so small as to have little effect on the study results or if cases and controls are matched on calendar time—that is, controls are selected on the same date as the onset of disease in the cases.
The Cohort Approach
Another way of ensuring that cases and controls are comparable is to draw them from the same cohort. In this situation, the study is said to be a nested case-control study (it is “nested” in the cohort).
In the era of large databases and powerful computers, why not just analyze cohort data as a cohort study rather than a case-control study? After all, the inefficiency of including many exposed members of the cohort, even though few of them will experience the outcome, could be overcome by computing power. The usual reason for case-control analyses of cohort data is that some of the study variables, especially some covariates, may not be available in the cohort database and, therefore, have to be gathered from other sources for each patient in the study. Obtaining the missing information from medical records, questionnaires, genetic analyses, and linkage to other databases can be very expensive and time-consuming. Therefore, there is a practical advantage to having to assemble this information only for cases and a sample of non-cases in the cohort, not every member of the cohort.
With nested case-control studies, there is an opportunity to obtain both a crude measures of incidence from a cohort analysis and a strong estimate of relative risk, that takes into account a rich set of covariates, from a case-control analysis. With this information one has the full set of risk described in Chapter 5—absolute risk for exposed and non-exposed people, relative risk, attributable risk, and population risks.
The bisphosphonate example illustrates the advantages of complementary cohort and case control analyses. A cohort analysis, taking only age into account, showed that the increase in absolute risk of atypical fractures related to bisphosphonate use was five cases per 10,000 patient-years. Collection of data on covariates was done by linking to other databases and was presumably too resource-intensive to be done on the entire national sample. With these data for cases and controls, a much more credible estimate of relative risk was possible in the case-control analysis. The estimate of relative risk of 33 from the case-control analysis was consistent with the crude relative risk from the cohort analysis (not accounting for potential confounders other than age), which was 47. Because of the two analyses, both cohort and case-control, the authors could point out that the relative risk of atypical fracture was large but the absolute risk was small.
Hospital and Community Controls
If population- or cohort-based sampling is not possible, a fallback position is to select controls in such a way that the selection seems to produce controls that are comparable to cases. For example, if cases are selected from a hospital ward, the controls might be selected from patients with different diseases, apparently unrelated to the exposure and disease of interest, in the same hospital. As pointed out earlier, for most risk factors and diseases, case-control studies in health care settings are more fallible than population- or cohort-based sampling because hospitalized patients are usually a biased sample of all people in the community, the people to whom the results should apply.
Another approach is to obtain controls from the community served by the hospital. However, many hospitals do not draw patients exclusively from the surrounding community; some people in the community go to other hospitals, and some people in other communities pass up their own neighborhood hospital to go to the study hospital. As a result, cases and controls may be systematically different in ways that distort the exposure-disease relationship.
Multiple Control Groups
If none of the available control groups seems ideal, one can see how choice of controls affects results by selecting several control groups with apparently complementary scientific strengths and weaknesses. Similar estimates of relative risk obtained using different control groups is evidence against bias because it is unlikely that the same biases would affect otherwise dissimilar groups in the same direction and to the same extent. If the estimates of relative risks are different, it is a signal that one or more are biased and the reasons need to be investigated.
Example
In the helmets and head injury example (2), the main control group was uninjured people skiing or snowboarding on the same hills on the same days, but one could imagine disadvantages to these controls, such as their not having similar risk-taking behavior to cases. To examine the effect of choice of control group on results, the investigators repeated the analyses with a different control group—skiers with other injuries. The estimated relative risk was similar—a reduction in risk of 55% rather than 60% with the original control group— suggesting that choice of control group did not substantially affect results.
Related posts:



Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


