Fig. 9.1
Illustration of image-guided radiotherapy. Red contours indicate the prostates
Many methods have been proposed to address this paramount yet compelling segmentation problem. For example, Freedman et al. [10] proposed to segment the prostate in CT images by matching the probability distributions of photometric variables (e.g., voxel intensity). Costa et al. [11] proposed the coupled 3D deformable models by considering the nonoverlapping constraint from the bladder. Foskey et al. [12] proposed a deflation method to explicitly eliminate bowel gas before 3D deformable registration. Chen et al. [13] incorporated the anatomical constraints from the rectum to assist the deformable segmentation of the prostate. Haas et al. [14] used 2D flood fill with the shape guidance to localize the prostate in CT images. Ghosh et al. [15] proposed a genetic algorithm with prior knowledge in the form of texture and shape. Although these methods have shown the effectiveness in CT prostate segmentation, their segmentation accuracy is very limited (usually with the overlap ratio (Dice similarity coefficient (DSC)) around 0.8), which can be explained by two factors. First, most of these methods rely only on the image intensity/gradient information to localize the prostate boundary. As shown in Fig. 9.1, due to the indistinct prostate boundary in CT images, simple intensity features are neither reliable nor sufficient to accurately localize the prostate. While several deformable segmentation methods [11, 13] utilized the spatial relationship of the prostate to its nearby organs (e.g., the rectum and bladder) to prevent the over-segmentation of the prostate, these strategies improve only the robustness, not the accuracy of the segmentation. Second, the majority of these methods overlook the information that is inherent in the IGRT workflow. In fact, at each treatment day, several CT scans of the same patient have already been acquired and segmented in the planning day and the previous treatment days. These valuable patient-specific images can be exploited to largely improve patient-specific prostate segmentation.
In the following sections, we will first introduce four recently developed machine learning methods to address the aforementioned challenges by automatically learning the effective features from the previously acquired data of the same patient for accurate prostate localization in CT images. Then, an extension to segmentation of MR prostate images is further presented.
9.3 Learning-Based Prostate Segmentation in CT and MR Images
9.3.1 Learning-Based Landmark Detection for Fast Prostate Localization in Daily Treatment CTs
In this section, we will introduce an application of boosting techniques in automatic landmark detection for fast prostate localization. Moreover, we will show how the accuracy of landmark detection and prostate localization can be further improved within the IGRT setting by adopting a novel method – namely, incremental learning with selective memory (ILSM) – to gradually incorporate the patient-specific information into the general population-based landmark detectors during the treatment course.
In the machine learning field, boosting refers to a technique which sequentially trains a list of weak classifiers to form a strong classifier [16]. One of the most successful applications of boosting is the robust real-time face detection method developed by Paul Viola and Michael J. Jones [16]. In their method, they combined Haar features with the boosting algorithm to learn a cascade of classifiers for efficient face detection. This idea can also be used to detect the anatomical landmark in medical images, which we call learning-based landmark detection. In such methods, the landmark detection is formulated as a classification problem. Specifically, for each image, voxels close to the specific landmark are positive and all others are negatives. In the training stage, the cascade learning framework is applied to learn a sequence of classifiers for gradually separating negatives from positives (Fig. 9.2). Compared to learning a single classifier, cascade learning has shown better classification accuracy and runtime efficiency [17, 18]. Mathematically, cascade learning can be formulated as:

Fig. 9.2
Illustration of cascade learning
Input: Positive voxel set X P , negative voxel set X N , and label set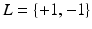 .
.
Classifier: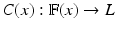 , where
, where 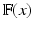 denotes the appearance features of a voxel x.
denotes the appearance features of a voxel x.
Initial set: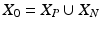 .
.
Objective: Optimize C k ,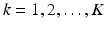 , such that
, such that
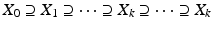 ,
, 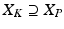 , and
, and 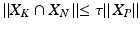
where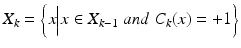 and τ controls the tolerance ratio of false positives.
and τ controls the tolerance ratio of false positives.
Here, the cascade classifiers C k , 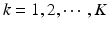 , are optimized sequentially. As shown in Eq. (9.1), C k is optimized to minimize the false positives left over by the previous
, are optimized sequentially. As shown in Eq. (9.1), C k is optimized to minimize the false positives left over by the previous 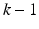 classifiers:
classifiers:
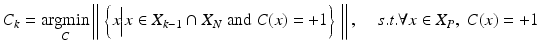
where 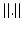 denotes the cardinality of a set. It is worth noting that the constraint in Eq. (9.1) can be simply satisfied by adjusting the threshold of classifier C k to make sure that all positive training samples are correctly classified. This cascade learning framework is general to any image feature and classifier. In the conventional cases, extended Haar wavelets [18–20] and AdaBoost classifier [16] are typically employed.
denotes the cardinality of a set. It is worth noting that the constraint in Eq. (9.1) can be simply satisfied by adjusting the threshold of classifier C k to make sure that all positive training samples are correctly classified. This cascade learning framework is general to any image feature and classifier. In the conventional cases, extended Haar wavelets [18–20] and AdaBoost classifier [16] are typically employed.
, are optimized sequentially. As shown in Eq. (9.1), C k is optimized to minimize the false positives left over by the previous classifiers:(9.1)
denotes the cardinality of a set. It is worth noting that the constraint in Eq. (9.1) can be simply satisfied by adjusting the threshold of classifier C k to make sure that all positive training samples are correctly classified. This cascade learning framework is general to any image feature and classifier. In the conventional cases, extended Haar wavelets [18–20] and AdaBoost classifier [16] are typically employed.Once the cascade classifiers {C k (x)} are learned, they have captured the appearance characteristics of the specific anatomical landmark. Given a testing image, the learned cascade is applied to each voxel. The voxel with the highest classification score after going through the entire cascade is selected as the detected landmark. To increase the efficiency and robustness of the detection procedure, a multiscale scheme is further adopted. Specifically, the detected landmark in the coarse resolution serves as the initialization for landmark detection in a following finer resolution, in which the landmark is only searched within a local neighborhood centered by the initialization. In this way, in the fine resolution, the search space is limited to a small neighborhood around the coarse-level detection, instead of the entire image domain, thus, making the detection procedure more robust to local minima.
We can adopt the learning-based landmark detection method to detect seven key landmarks of the prostate (Fig. 9.3), which are the prostate centroid, the apex center, the base center, and four extreme points in the middle slice, respectively.
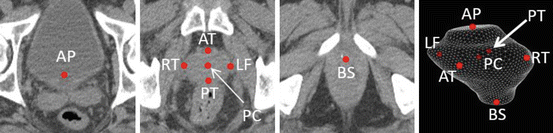
Fig. 9.3
Seven prostate landmarks: prostate center (PC), right lateral point (RT), left lateral point (LF), posterior point (PT), anterior point (AT), base center (BS), and apex center (AP)
After seven landmarks are automatically detected in the new treatment image, we can use them to align the patient-specific prostate shapes delineated in the previous planning and treatment days onto the current treatment image for fast localization. Specifically, a rigid transform is estimated between the detected landmarks in the current treatment image and the corresponding ones in the previous planning or treatment image for shape alignment. By aligning all previous patient-specific prostate shapes onto the current treatment image, a simple label fusion technique like majority voting can be used for fusing different labeling results to derive a final segmentation of the prostate. To take into account those wrongly detected landmarks, the RANSAC point-set matching algorithm can also be combined with multi-atlas segmentation to improve the robustness (for details, please refer to [21]). This landmark-based prostate localization strategy is very fast and takes only a few seconds to localize the whole prostate in a new treatment image.
Using cascade learning, one can learn anatomy detectors from the training images of different patients (population–based learning). However, since intra-patient anatomy variations are much less noticeable than inter-patient variations, patient-specific appearance information available in the IGRT workflow should be exploited in order to improve the detection accuracy for an individual patient. Unfortunately, the number of patient-specific images is often very limited, especially at the beginning of IGRT. To overcome this problem, one may apply random spatial/intensity transformations to produce more “synthetic” training samples with larger variability. However, these artificially created transformations may not capture the real intra-patient variations, e.g., the uncertainty of bowel gas and filling (Fig. 9.4). As a result, cascade learning, using only patient-specific data (pure patient–specific learning), often suffers from overfitting. One can also mix population and patient-specific images for training (mixture learning). However, since patient-specific images are the “minority” in the training samples, detectors trained by mixed samples might not capture patient-specific characteristics very well.
Fig. 9.4
Inter- and intra-patient prostate shape and appearance variations. Red points denote the prostate center. Each row represents prostate shapes and images for the same patient
9.3.1.1 Incremental Learning with Selective Memory (ILSM)
To address the above problem, a novel learning scheme, namely, incremental learning with selective memory (ILSM), is proposed to combine the general information in the population images with the individual information in the patient-specific images. Specifically, population-based landmark detectors serve as an initial appearance model and are subsequently “personalized” by the limited patient-specific data. ILSM consists of backward pruning to discard obsolete population appearance information and forward learning to incorporate the online-learned patient-specific appearance characteristics.
Notation
Denote  as the population-based landmark detector learned by using the cascade learning framework. X P pat and X N pat are positives and negatives from the patient-specific training images (i.e., previous planning or treatment images), respectively. D(x) denotes the class label (landmark vs non-landmark) of voxel x predicted by landmark detector D.
as the population-based landmark detector learned by using the cascade learning framework. X P pat and X N pat are positives and negatives from the patient-specific training images (i.e., previous planning or treatment images), respectively. D(x) denotes the class label (landmark vs non-landmark) of voxel x predicted by landmark detector D.
as the population-based landmark detector learned by using the cascade learning framework. X P pat and X N pat are positives and negatives from the patient-specific training images (i.e., previous planning or treatment images), respectively. D(x) denotes the class label (landmark vs non-landmark) of voxel x predicted by landmark detector D.Backward Pruning
The general appearance model learned from the population is not necessarily applicable to the specific patient. More specifically, the anatomical landmarks in the patient-specific images (positives) may be classified as negatives by the population-based anatomy detectors, i.e., 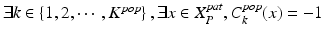 . In order to discard these parts of the population appearance model that do not fit the patient-specific characteristics, we propose backward pruning to tailor the population-based detector. As shown in Algorithm 9.1, in backward pruning, the cascade is pruned from the last level until all patient-specific positives successfully pass through the cascade. This is equivalent to searching for the maximum number of cascade levels that could be preserved from the population-based anatomy detector (Eq. 9.2):
. In order to discard these parts of the population appearance model that do not fit the patient-specific characteristics, we propose backward pruning to tailor the population-based detector. As shown in Algorithm 9.1, in backward pruning, the cascade is pruned from the last level until all patient-specific positives successfully pass through the cascade. This is equivalent to searching for the maximum number of cascade levels that could be preserved from the population-based anatomy detector (Eq. 9.2):
. In order to discard these parts of the population appearance model that do not fit the patient-specific characteristics, we propose backward pruning to tailor the population-based detector. As shown in Algorithm 9.1, in backward pruning, the cascade is pruned from the last level until all patient-specific positives successfully pass through the cascade. This is equivalent to searching for the maximum number of cascade levels that could be preserved from the population-based anatomy detector (Eq. 9.2):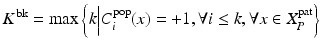
(9.2)
Algorithm 9.1. Backward Pruning Algorithm
Input: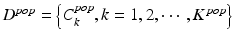
– the population-based detector
X P pat – patient-specific positive samples
Output: D bk – the tailored population-based detector
Init: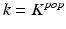 ,
, 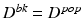 .
.
while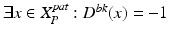 do
do
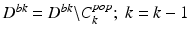
end while
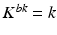
return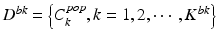
Forward Learning
Once the population cascade has been tailored, the remaining cascade of classifiers encodes the population appearance information that is consistent with the patient-specific characteristics. Yet, until now no real patient-specific information has been incorporated into the cascade. More specifically, false positives might exist in the patient-specific samples, i.e., 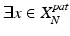 ,
, 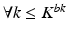 ,
, 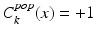 . In the forward learning stage, we use the remaining cascade from the backward pruning algorithm as an initialization, and re-apply the cascade learning to eliminate the patient-specific false positives left over by the previously inherited population classifiers. As shown in Algorithm 9.2, a greedy strategy is adopted to sequentially optimize a set of additional patient-specific classifiers
. In the forward learning stage, we use the remaining cascade from the backward pruning algorithm as an initialization, and re-apply the cascade learning to eliminate the patient-specific false positives left over by the previously inherited population classifiers. As shown in Algorithm 9.2, a greedy strategy is adopted to sequentially optimize a set of additional patient-specific classifiers 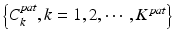 .
.
, , . In the forward learning stage, we use the remaining cascade from the backward pruning algorithm as an initialization, and re-apply the cascade learning to eliminate the patient-specific false positives left over by the previously inherited population classifiers. As shown in Algorithm 9.2, a greedy strategy is adopted to sequentially optimize a set of additional patient-specific classifiers .Algorithm 9.2. Forward Learning Algorithm
Input: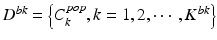
– the tailored population-based detector
X P pat – patient-specific positive samples
X N pat – patient-specific negative samples
Output: D pat – patient-specific detector
Init: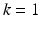 ,
, 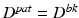
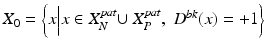
while9.3 below
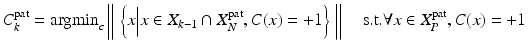
( 9.3)
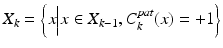
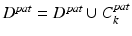 ;
; 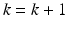
end while
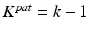
return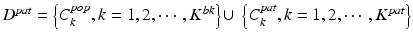
 denotes the cardinality of a set. τ is the parameter controlling the tolerance of false positives.
denotes the cardinality of a set. τ is the parameter controlling the tolerance of false positives.
After backward pruning and forward learning, the personalized anatomy detector includes two groups of classifiers (Fig. 9.5). While 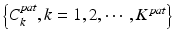 encodes patient-specific characteristics,
encodes patient-specific characteristics, 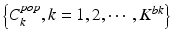 contains population information that is individualized to this specific patient. This population information effectively remedies the limited variability from the small number of patient-specific training images.
contains population information that is individualized to this specific patient. This population information effectively remedies the limited variability from the small number of patient-specific training images.

encodes patient-specific characteristics, contains population information that is individualized to this specific patient. This population information effectively remedies the limited variability from the small number of patient-specific training images.Fig. 9.5
Incrementally learned landmark detector
9.3.2 Experimental Results
Our experimental dataset was acquired from the University of North Carolina at Chapel Hill. In total, we have 25 patients with 349 CT images. Each patient has one planning scan and multiple treatment scans. The prostates and seven landmarks in all CT images have been manually delineated by an expert to serve as the ground truth. We use fivefold cross-validation to evaluate our method and compare it with other methods. To emulate the real clinical setting, for prostate localization in the treatment day  , we use N previous treatment images and also the planning image as patient-specific training data (Fig. 9.1). From our observations, we found that, when N reaches 4, there was negligible accuracy gained from performing additional ILSMs. Therefore, after treatment day 4, we do not perform ILSM to further refine the patient-specific landmark detectors; instead, we directly adopt the existing detectors for prostate localization. The following reported performances of ILSM are computed using up to 5 patient-specific training images (4 treatment images + 1 planning image). Details about the algorithm parameters can be found in [21].
, we use N previous treatment images and also the planning image as patient-specific training data (Fig. 9.1). From our observations, we found that, when N reaches 4, there was negligible accuracy gained from performing additional ILSMs. Therefore, after treatment day 4, we do not perform ILSM to further refine the patient-specific landmark detectors; instead, we directly adopt the existing detectors for prostate localization. The following reported performances of ILSM are computed using up to 5 patient-specific training images (4 treatment images + 1 planning image). Details about the algorithm parameters can be found in [21].
, we use N previous treatment images and also the planning image as patient-specific training data (Fig. 9.1). From our observations, we found that, when N reaches 4, there was negligible accuracy gained from performing additional ILSMs. Therefore, after treatment day 4, we do not perform ILSM to further refine the patient-specific landmark detectors; instead, we directly adopt the existing detectors for prostate localization. The following reported performances of ILSM are computed using up to 5 patient-specific training images (4 treatment images + 1 planning image). Details about the algorithm parameters can be found in [21].9.3.3 Comparison with Traditional Learning-Based Approaches
To illustrate the effectiveness of our learning framework, we compared ILSM with four different learning-based approaches. All of these methods localize the prostate through learning-based anatomy detection with the same features, classifiers, and cascade framework. Their differences lie in the training images and learning strategies, which are shown in Table 9.1. Note that for all patient-specific training images, artificial transformations are applied to increase the intersubject variability.
Table 9.1
Difference between ILSM and four learning-based methods
POP | PPAT | MIX | IL | ILSM | ||
|---|---|---|---|---|---|---|
Training images | Population | √ | √ | √ | √ | |
Patient specific | √ | √ | √ | √ | ||
Learning strategies | Cascade learning | √ | √ | √ | √ | √ |
Backward pruning | √ | |||||
Forward learning | √ | √ | ||||
Table 9.2 compares the four learning-based approaches with ILSM on landmark detection errors. We can see that ILSM outperforms other four learning-based approaches on all seven anatomical landmarks. Table 9.3 compares the four learning-based approaches with ILSM on overlap ratios (DSC). To exclude the influence of multi-atlas RANSAC, only a single shape atlas (i.e., the planning prostate shape) is used for localization. Here, “acceptance rate” denotes the percentage of images where an algorithm performs with higher accuracy than inter-operator variability (DSC = 0.81) [22]. According to our experienced clinician, these results can be accepted with minimal manual editing (<20 %). We can see that ILSM achieves the best localization accuracy among all methods. Not surprisingly, by utilizing patient-specific information, all three methods (i.e., PPAT, MIX, and IL) outperform POP. However, their performances are still inferior to ILSM, which shows the effectiveness of ILSM in combining both population- and patient-specific characteristics.
Table 9.2
Quantitative comparison of landmark detection error (mm) between ILSM and four learning-based methods
POP | PPAT | MIX | IL | ILSM | |
|---|---|---|---|---|---|
PC | 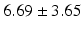 | 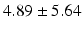 | 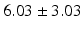 | 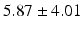 | 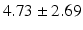 |
RT | 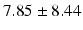 | 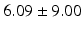 | 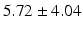 | 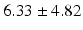 | 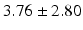 |
LF | 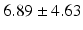 | 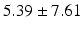 | 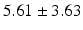 | 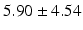 | 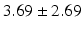 |
PT | 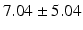 | 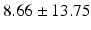 | 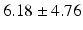 | 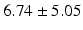 | 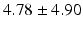 |
AT | 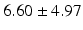 | 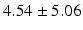 | 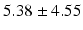 | 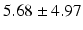 | 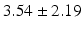 |
BS | 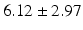 | 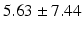 | 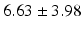 | 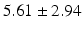 | 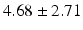 |
AP | 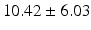 | 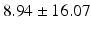 | 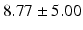 | 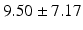 | 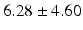 |
Average | 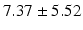 | 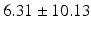 | 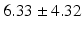 | 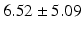 | 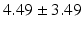 |
p-value | 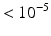 | 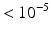 | 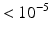 | 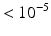 | n/a |
Table 9.3
Quantitative comparisons on prostate localization between ILSM and four learning-based methods
POP (S) | PPAT (S) | MIX (S) | IL (S) | ILSM (S) | ILSM (M) | |
|---|---|---|---|---|---|---|
Mean DSC | 0.81 ± 0.10 | 0.84 ± 0.15 | 0.83 ± 0.09 | 0.83 ± 0.09 | 0.87 ± 0.06 | 0.88 ± 0.06 |
Acceptance rate (%) | 66 | 85 | 74 | 77 | 90 | 91 |
9.3.4 Sparse Representation-Based Classification for Treatment Image Segmentation
Sparse representation as an emerging technique has become the focus of much recent research in machine learning [23, 24], signal processing [25], and computer vision [26, 27]. It has been successfully applied in many fields, such as compressive sensing [28] and face recognition [29], and has achieved considerable improvements over previous methods in those fields. In this section, we present a sparse representation-based classification method to segment the prostate from treatment images.
Sparse representation models data with linear combinations of a few elements from a learned dictionary. Like the traditional data representation methods (e.g., wavelet and Fourier transform), the sparse representation method has a set of basis elements, which column-wisely form a dictionary. These basis elements do not need to be orthogonal or predefined, which largely differentiates them from the traditional data representation methods. Therefore, the dictionary for sparse representation is usually learned through a process called dictionary learning so that the learned dictionary can be well tailored with respect to a specific task (e.g., reconstruction and classification). Given a learned dictionary 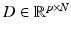 , which has N p-dimensional basis elements, the goal of sparse representation is to select a few basis elements for best representing the input signal
, which has N p-dimensional basis elements, the goal of sparse representation is to select a few basis elements for best representing the input signal 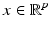 . Mathematically, it can be formulated as the following sparse coding problem:
. Mathematically, it can be formulated as the following sparse coding problem:
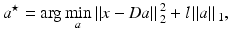
where 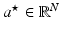 is called sparse representation or sparse code of x with respect to the dictionary D,|| α ||1 is the L1 norm of α, and λ is a parameter that controls the sparsity of
is called sparse representation or sparse code of x with respect to the dictionary D,|| α ||1 is the L1 norm of α, and λ is a parameter that controls the sparsity of 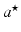 or the number of nonzero entries in
or the number of nonzero entries in 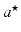 . The larger λ is, the sparser
. The larger λ is, the sparser 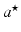 is and the fewer nonzero entries
is and the fewer nonzero entries 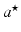 has.
has.
, which has N p-dimensional basis elements, the goal of sparse representation is to select a few basis elements for best representing the input signal . Mathematically, it can be formulated as the following sparse coding problem:(9.4)
is called sparse representation or sparse code of x with respect to the dictionary D,|| α ||1 is the L1 norm of α, and λ is a parameter that controls the sparsity of or the number of nonzero entries in . The larger λ is, the sparser is and the fewer nonzero entries has.Sparse representation-based classification (SRC) [29] was recently proposed and has been widely used for face recognition. In SRC, to classify a new sample, all training samples from different classes are used to represent it in a competitive manner, and the class label is determined by choosing the class that best reconstructs it. Specifically, the training samples belonging to the same class are first column-wisely grouped into sub–dictionaries, which are further combined to form a global dictionary 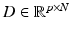
![$$ D=\left[{D}_1,\cdots,\;{D}_i,\cdots,\;{D}_K\right] $$](/wp-content/uploads/2016/10/A320877_1_En_9_Chapter_Equ5.gif)
![$$ =\left[{d}_{1,1},{d}_{1,2},\cdots, {d}_{i,j},\cdots, {d}_{K,{N}_K}\right], $$](/wp-content/uploads/2016/10/A320877_1_En_9_Chapter_Equ6.gif)
where D i is the sub-dictionary of class i, d i,j is the jth training sample of class i, K is the total number of classes, N K is the total number of training samples in class K, and N is the total number of training samples equal to 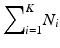 . To classify a new sample
. To classify a new sample 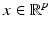 , its sparse code
, its sparse code 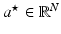 is first computed with respect to the global dictionary D according to Eq. (9.4). Then the residue with respect to each class is calculated:
is first computed with respect to the global dictionary D according to Eq. (9.4). Then the residue with respect to each class is calculated:
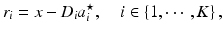
where 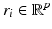 is the residue with respect to class i and
is the residue with respect to class i and 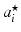 carries entries of
carries entries of 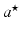 corresponding to the indices of columns in D belonging to D i . Finally, the signal x is classified to the class with the minimum L2 residue norm.
corresponding to the indices of columns in D belonging to D i . Finally, the signal x is classified to the class with the minimum L2 residue norm.
(9.5)
(9.6)
. To classify a new sample , its sparse code is first computed with respect to the global dictionary D according to Eq. (9.4). Then the residue with respect to each class is calculated:(9.7)
is the residue with respect to class i and carries entries of corresponding to the indices of columns in D belonging to D i . Finally, the signal x is classified to the class with the minimum L2 residue norm.To segment the prostate in daily treatment images, sparse representation-based classification is used to enhance the prostate in CT images by pixel-wise classification in order to overcome the poor contrast of the prostate images. Then, based on the classification results, the previously segmented prostates of the same patient can be aligned onto the current image for multi-atlas-based segmentation [21]. Since our segmentation is guided by the classification, the segmentation accuracy highly depends on the classification performance. However, the conventional SRC suffers from two main limitations when applied to the pixel-wise classification. First, the conventional SRC cannot be directly adapted to the large-scale problem where the size of training samples is huge. Second, when training samples of different classes are highly correlated, the classification performance of the conventional SRC is limited. To overcome these limitations, especially for the purpose of segmentation, we propose four extensions to the SRC, which are elaborated in the following paragraphs one by one.
9.3.5 Discriminant Sub-dictionary Learning
In pixel-wise classification, it is common for different classes to have similar training samples. In such a case, the performance of SRC is limited. Discriminant sub-dictionary learning aims to learn sub-dictionaries as distinct as possible. Here, we propose to combine feature selection with the dictionary learning method as a way to learn discriminant sub-dictionaries. First, a feature selection technique is used to select discriminant features so that the output training samples of different classes are as distinct as possible. A dictionary learning method is subsequently adopted to learn a compact representation of these discriminant training samples in order to make the size of the sub-dictionary feasible.
In the context of prostate segmentation, each voxel needs to be identified as prostate or background. Considering that each training sample is represented by a feature vector, which can be intensity or image features, the selection of features discriminant between prostate and background classes aims to best distinguish prostate voxels from background voxels. In this work, feature ranking, based on the Fisher separation criterion (FSC) [30], is adopted to select those discriminant features. Specifically, for each feature f, we compute its FSC score as 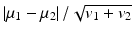 , where μ 1 and μ 2, v 1 and v 2 are the sample means and variances of feature f in prostate and background classes, respectively. Features with high FSC scores are considered discriminant and, thus, are selected while features with low FSC scores are discarded in the final feature-based representation.
, where μ 1 and μ 2, v 1 and v 2 are the sample means and variances of feature f in prostate and background classes, respectively. Features with high FSC scores are considered discriminant and, thus, are selected while features with low FSC scores are discarded in the final feature-based representation.
, where μ 1 and μ 2, v 1 and v 2 are the sample means and variances of feature f in prostate and background classes, respectively. Features with high FSC scores are considered discriminant and, thus, are selected while features with low FSC scores are discarded in the final feature-based representation.After feature selection, due to the large size of training samples in pixel-wise classification, it is practically infeasible to directly use them to form sub-dictionaries. For storage and computational efficiency, it is necessary to adopt a dictionary learning method to learn a compact representation of those discriminant training samples for each class. In this work, we use the K-means clustering method that preserves the discriminant characteristics of training samples.
Related posts:
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


