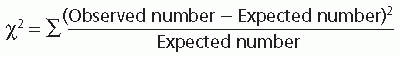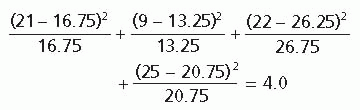Learning from clinical experience, whether during formal research or in the course of patient care, is impeded by two processes: bias and chance. As discussed in
Chapter 1, bias is systematic error, the result of any process that causes observations to differ systematically from the true values. Much of this book has been about where bias might lurk, how to avoid it when possible, and how to control for it and estimate its effects when bias is unavoidable.
On the other hand, random error, resulting from the play of chance, is inherent in all observations. It can be minimized but never avoided altogether. This source of error is called “random” because, on average, it is as likely to result in observed values being on one side of the true value as on the other.
Many of us tend to underestimate the importance of bias relative to chance when interpreting data, perhaps because statistics are quantitative and appear so definitive. We might say, in essence, “If the statistical conclusions are strong, a little bit of bias can’t do much harm.” However, when data are biased, no amount of statistical elegance can save the day. As one scholar put it, perhaps taking an extreme position, “A well designed, carefully executed study usually gives results that are obvious without a formal analysis and if there are substantial flaws in design or execution a formal analysis will not help” (
2).
In this chapter, we discuss chance mainly in the context of controlled clinical trials because it is the simplest way of presenting the concepts. However, statistics are an element of all clinical research, whenever one makes inferences about populations based on information obtained from samples. There is always a possibility that the particular sample of patients in a study, even though selected in an unbiased way, might not be similar to the population of patients as a whole. Statistics help estimate how well observations on samples approximate the true situation.
TWO APPROACHES TO CHANCE
Two general approaches are used to assess the role of chance in clinical observations.
One approach, called
hypothesis testing, asks whether an effect (difference) is present or is not by using statistical tests to examine the hypothesis
(called the “null hypothesis”) that there is no difference. This traditional way of assessing the role of chance, associated with the familiar “
P value,” has been popular since statistical testing was introduced at the beginning of the 20th century. The hypothesis testing approach leads to dichotomous conclusions: Either an effect is present or there is insufficient evidence to conclude an effect is present.
The other approach, called estimation, uses statistical methods to estimate the range of values that is likely to include the true value—of a rate, measure of effect, or test performance. This approach has gained popularity recently and is now favored by most medical journals, at least for reporting main effects, for reasons described below.
HYPOTHESIS TESTING
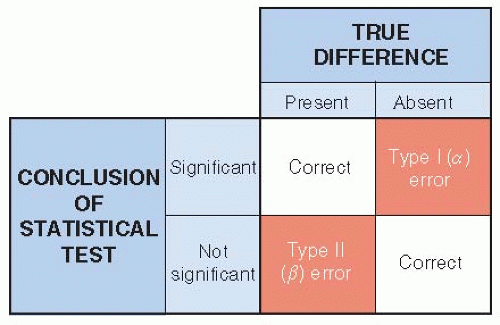
In the usual situation, the principal conclusions of a trial are expressed in dichotomous terms, such as a new treatment is either better or not better than usual care, corresponding to the results being either
statistically significant (unlikely to be purely by chance) or not. There are four ways in which the statistical conclusions might relate to reality (
Fig. 11.1).
Two of the four possibilities lead to correct conclusions: (i) The new treatment really is better, and that is the conclusion of the study; and (ii) the treatments really have similar effects, and the study concludes that a difference is unlikely.
Concluding That a Treatment Works
Most statistics encountered in the medical literature concern the likelihood of a type I error and are
expressed by the familiar
P value. The
P value is a quantitative estimate of the probability that differences in treatment effects in the particular study at hand could have happened by chance alone, assuming that there is in fact no difference between the groups. Another way of expressing this is that
P is an answer to the question, “If there were no difference between treatment effects and the trial was repeated many times, what proportion of the trials would conclude that the difference between the two treatments was at least as large as that found in the study?”
In this presentation, P values are called Pa, to distinguish them from estimates of the other kind of error resulting from random variation, type II errors, which are referred to as Pβ. When a simple P is found in the scientific literature, it ordinarily refers to Pα.
The kind of error estimated by Pα applies whenever one concludes that one treatment is more effective than another. If it is concluded that the Pα exceeds some limit (see below) so there is no statistical difference between treatments, then the particular value of Pα is not as relevant; in that situation, Pβ (probability of type II error) applies.
Dichotomous and Exact P Values
It has become customary to attach special significance to P values below 0.05 because it is generally agreed that a chance of <1 in 20 is a small enough risk of being wrong. A chance of 1 in 20 is so small, in fact, that it is reasonable to conclude that such an occurrence is unlikely to have arisen by chance alone. It could have arisen by chance, and 1 in 20 times it will, but it is unlikely.
Differences associated with
Pα < 0.05 are called
statistically significant. However, setting a cutoff point at 0.05 is entirely arbitrary. Reasonable people might accept higher values or insist on lower ones, depending on the consequences of a false-positive conclusion in a given situation. For example, one might be willing to accept a higher chance of a false-positive statistical test if the disease is severe, there is currently no effective treatment, and the new treatment is safe. On the other hand, one might be reluctant to accept a false-positive test if usual care is effective and the new treatment is dangerous or much more expensive. This reasoning is similar to that applied to the importance of false-positive and false-negative diagnostic tests (
Chapter 8).
To accommodate various opinions about what is and is not unlikely enough, some researchers report the exact probabilities of P (e.g., 0.03, 0.07, 0.11), rather than lumping them into just two categories (≤0.05 or >0.05). Users are then free to apply their own preferences for what is statistically significant. However, P values >1 in 5 are usually reported as simply P > 0.20, because nearly everyone can agree that a probability of a type I error >1 in 5 is unacceptably high. Similarly, below very low P values (e.g., P < 0.001) chance is a very unlikely explanation for an observed difference, and little further information is conveyed by describing this chance more precisely.
Another approach is to accept the primacy of P ≤ 0.05 and describe results that come close to that standard with terms such as “almost statistically significant,” “did not achieve statistical significance,” “marginally significant,” or “a trend.” These valueladen terms suggest that the finding should have been statistically significant but for some annoying reason was not. It is better to simply state the result and exact P value (or point estimate and confidence interval, see below) and let the reader decide for him or herself how much chance could have accounted for the result.
Statistical Significance and Clinical Importance
A statistically significant difference, no matter how small the P, does not mean that the difference is clinically important. A P value of <0.0001, if it emerges from a well-designed study, conveys a high degree of confidence that a difference really exists but says nothing about the magnitude of that difference or its clinical importance. In fact, trivial differences may be highly statistically significant if a large enough number of patients are studied.
On the other hand, very unimpressive P values can result from studies with strong treatment effects if there are few patients in the study.
Statistical Tests
Statistical tests are used to estimate the probability of a type I error. The test is applied to the data to obtain a numerical summary for those data called a test statistic. That number is then compared to a sampling distribution to come up with a probability of a type I error (
Fig. 11.2). The distribution is under the
null hypothesis, the proposition that there is no true difference in outcome between treatment groups. This device is for mathematical reasons, not because “no difference” is the working scientific hypothesis of the investigators conducting the study. One ends up rejecting the null hypothesis (concluding there is a difference) or failing to reject it (concluding that there is insufficient evidence in support of a difference). Note that not finding statistical significance is not the same as there being no difference. Statistical testing is not able to establish that there is no difference at all.
Some commonly used statistical tests are listed in
Table 11.1. The validity of many tests depends on certain assumptions about the data; a typical assumption is that the data have a normal distribution. If the data do not satisfy these assumptions, the resulting
P value may be misleading. Other statistical tests, called
non-parametric tests, do not make assumptions about the underlying distribution of the data. A discussion of how these statistical tests are derived and calculated and of the assumptions on which they rest can be found in any biostatistics textbook.
The chi-square (χ2) test for nominal data (counts) is more easily understood than most and can be used to illustrate how statistical testing works. The extent to which the observed values depart from what would have been expected if there were no treatment effect is used to calculate a P value.
When using statistical tests, the usual approach is to test for the probability that an intervention is either more or less effective than another to a statistically important extent. In this situation, testing is called two-tailed, referring to both tails of a bell-shaped curve describing the random variation in differences between treatment groups of equal value, where the two tails of the curve include statistically unlikely outcomes favoring one or the other treatment. Sometimes there are compelling reasons to believe that one treatment could only be better or worse than the other, in which case one-tailed testing is used, where all of the type I error (5%) is in one of the tails, making it easier to reach statistical significance.
Concluding That a Treatment Does Not Work
Some trials are unable to conclude that one treatment is better than the other. The risk of a false-negative result is particularly large in studies with relatively few patients or outcome events. The question then arises: How likely is a false-negative result (type II or β error)? Could the “negative” findings in such
trials have misrepresented the truth because these particular studies had the bad luck to turn out in a relatively unlikely way?
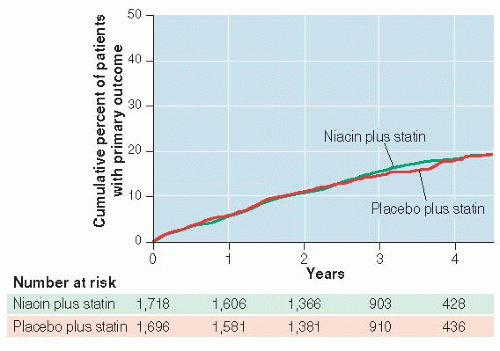
Visual presentation of negative results can be convincing. Alternatively, one can examine confidence intervals (see Point Estimates and Confidence Intervals, below) and learn a lot about whether the study was large enough to rule out clinically important differences if they existed.
Of course, reasons for false-negative results other than chance also need to be considered: biologic reasons such as too short follow-up or too small dose of niacin, as well as study limitations such as noncompliance and missed outcome events.
Type II errors have received less attention than type I errors for several reasons. They are more difficult to calculate. Also, most professionals simply prefer things that work and consider negative results unwelcome. Authors are less likely to submit negative studies to journals and when negative studies are reported at all, the authors may prefer to emphasize subgroups of patients in which treatment differences were found. Authors may also emphasize reasons other than chance to explain why true differences might have been missed. Whatever the reason for not considering the probability of a type II error, it is the main question that should be asked when the results of a study are interpreted as “no difference.”