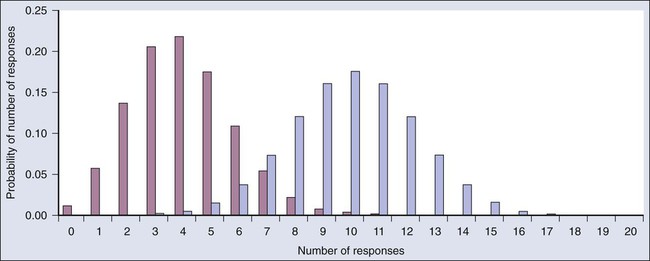
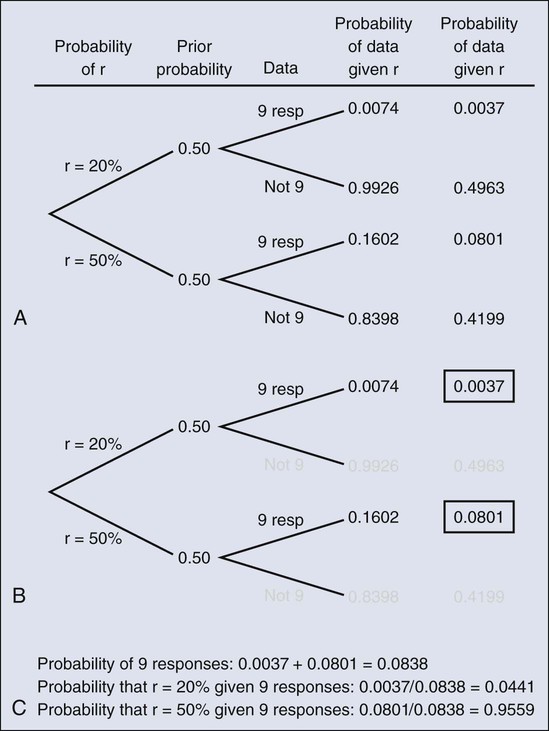
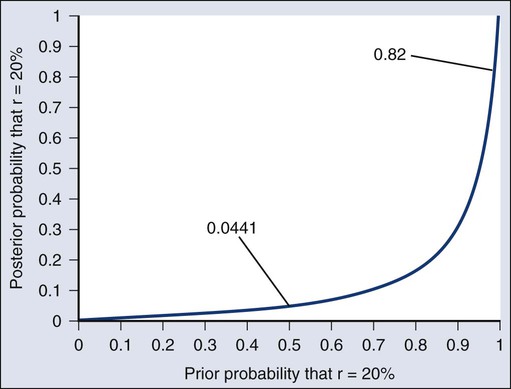
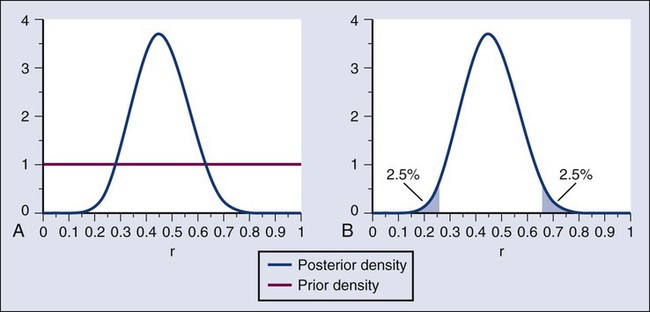
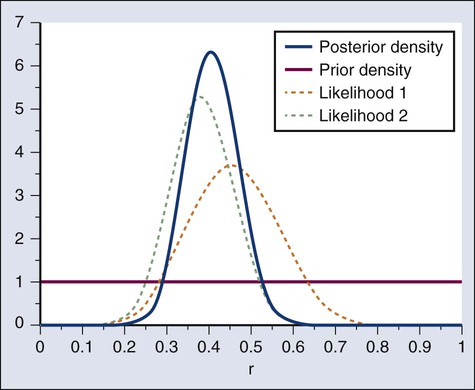
Donald A. Berry and Kevin R. Coombes • The process of conducting cancer research must change in the face of prohibitive costs and limited patient resources. • Biostatistics has a tremendous impact on the level of science in cancer research, especially in the design and conducting of clinical trials. • The Bayesian statistical approach to clinical trial design and conduct can be used to develop more efficient and effective cancer studies. • Modern technology and advanced analytic methods are directing the focus of medical research to subsets of disease types and to future trials across different types of cancer. • A consequence of the rapidly changing technology for generating “omics” data is that biological assays are often not stable long enough to discover and validate a model in a clinical trial. • Bioinformaticians must use technology-specific data normalization procedures and rigorous statistical methods to account for sample collecting, batch effects, multiple testing, confounding covariates, and any other potential biases. • Best practices in developing prediction models include public access to the information, rigorous validation of the model, and model lockdown prior to its use in patient care management. The Bayesian approach predates the frequentist approach. Thomas Bayes developed his treatise on inverse probabilities in the 1750s, and it was published posthumously in 1763 as “An Essay towards Solving a Problem in the Doctrine of Chances.” Laplace picked up the Bayesian thread in the first quarter of the nineteenth century with the publication of Théorie Analytique des Probabilités. The works of both scientists were important and had the potential to quantify uncertainty in medicine. Indeed, Laplace’s work influenced Pierre Louis in France in the second quarter of the nineteenth century as Louis developed his “numerical method.” Louis’ method involved simple tabulations of outcomes, an approach that was largely rejected by the medical establishment of the time. The stumbling block was not how to draw inferences from data tabulations.1 Rather, the counter argument and the prevailing medical attitude of the time was that each patient was unique and the patient’s doctor was uniquely suited to determine diagnosis and treatment. Vestiges of this attitude survive today. In the two hundred years after Bayes, the discipline of statistics was influenced by probability theory, and in particular, games of chance, dating to the early 1700s.4–4 This view focused on probability distributions of outcomes of experiments, assuming a particular value of a parameter. A simple example is the binomial distribution. This distribution gives the probabilities of outcomes of a specified number of tosses of a coin with known probability of heads, which is the distribution’s parameter. The binomial distribution continues to be important today. For example, it is used in designing cancer clinical trials in which the end point is dichotomous (tumor response or not, say) and assuming a predetermined sample size. Consider a single-arm clinical trial with the objective of evaluating r. The null value of r is taken to be 20%. The alternative value is r = 50%. The trial consists of treating n = 20 patients. The exact number of responses is not known in advance, but it is known to be either 0 or 1 or 2 on up to 20. The relevant probability distribution of the outcome is binomial, with one distribution for r = 20% and a second distribution for r = 50%. These distributions are shown in Figure 19-1, with red bars for r = 20% and blue bars for r = 50%. More generally, there is a different binomial distribution for each possible value of r. Both the frequentist and Bayesian approaches to clinical trial design and analysis utilize distributions such as those shown in Figure 19-1, but they use them differently. The frequentist approach to inference is based on error rates. A type I error is rejecting a null hypothesis when it is true, and a type II error is accepting the null hypothesis when it is false, in which case the alternative hypothesis is assumed to be true. It seems reasonable to reject the null, r = 20% (red bars in Fig. 19-1) in favor of the alternative, r = 50% (blue bars in Fig. 19-1) if the number of responses is sufficiently large. Candidate values of “large” might reasonably be where the red and blue bars in Figure 19-1 start to overlap, perhaps nine or greater, eight or greater, seven or greater, or six or greater. The type I error rates for these rejection rules are the respective sums of the heights of the red bars in Figure 19-1. For example, when the cut point is 9, the type I error rate is the sum of the heights of the red bars for 9, 10, 11, etc., which is 0.007387 + 0.002031 + 0.000462 + … = 0.0100. When the cut points are 8, 7, and 6, the respective type I error rates are 0.0321, 0.0867, and 0.1958. One convention is to define the cut point so that the type I error rate is no greater than 0.05. The largest of the candidate type I error rates that is less than 0.05 is 0.0321, the test that rejects the null hypothesis if there are eight or more responses. The type II error rate is calculated from the blue bars in Figure 19-1, where the alternative hypothesis is assumed to be true. The sum of the heights of the blue bars for 0 up to 7 responses is 0.1316. Convention is to consider the complementary quantity and call it “statistical power:” 0.8684, which rounds off to 87%. The distinction between “rate” and “probability” in the aforementioned description is important, and failing to discriminate these terms has led to much confusion in medical research.5 The “type I error rate” is a probability only when assuming that the null hypothesis is true. Probabilities of events requiring the truth of the null hypothesis are not available in the frequentist approach, and indeed this is a principal contrast with the Bayesian approach (described later). The calculation is intuitive when viewed as a tree diagram, as in Figure 19-2. Figure 19-2, A, shows the full set of probabilities. The first branching shows the two possible parameters, r = 20% and r = 50%. The probabilities shown in the figure, 0.50 for both, will be discussed later. The data are shown in the next branching, with the observed data, nine responses (nine resp) on one branch and all other data on the other. The probability of the data given r, which statisticians call the likelihood of r, is the height of the bar in Figure 19-1 corresponding to nine responses, the red bar for r = 20%, and the blue bar for r = 50%. The rightmost column in Figure 19-2, A, gives the probability of both the data and r along the branch in question. For example, the probability of r = 20% and “nine resp” is 0.50 multiplied by 0.0074. The probability of r = 20% given the experimental results depends on the probability of r = 20% without any condition, its so-called prior probability. The analog in finding the positive predictive value of a diagnostic test is the prevalence of the condition or disease in question. Prior probability depends on other evidence that may be available from previous studies of the same therapy in the same disease, or related therapies in the same disease or different diseases. Assessment may differ depending on the person making the assessment. Subjectivity is present in all of science; the Bayesian approach has the advantage of making subjectivity explicit and open.6 When the prior probability equals 0.50, as assumed in Figure 19-2, the posterior probability of r = 20% is 0.0441. Obviously, this is different from the frequentist P value of 0.0100 calculated earlier. Posterior probabilities and P values have very different interpretations. The P value is the probability of the actual observation, 9 responses, plus that of 10, 11, etc. responses, assuming the null distribution (the red bars in Fig. 19-1). The posterior probability conditions on the actual observation of nine responses and is the probability of the null hypothesis—that the red bars are in fact correct—but assuming that the true response rate is a priori equally likely to be 20% and 50%. As an example of such a report, Figure 19-3 shows the relationship between the prior and posterior probabilities. The figure indicates that the posterior probability is moderately sensitive to the prior. Someone whose prior probability of r = 20% is 0 or 1 will not be swayed by the data. However, as Figure 19-3 indicates, the conclusion that r = 20% has low probability is robust over a broad range of prior probabilities. A conclusion that r = 20% has moderate to high probability is possible only for someone who was convinced that r = 20% in advance of the trial. In the example, r was assumed to be either 20% or 50%. It would be unusual to be certain that r is one of two values and that no other values are possible. A more realistic example would be to allow r to have any value between 0 and 1 but to associate weights with different values depending on the degree to which the available evidence supports those values. In such a case, prior probabilities can be represented with a histogram (or density). A common assumption is one that reflects no prior information that any particular interval of values of r is more probable than any other interval of the same width. The corresponding density is flat over the entire interval from 0 to 1 and is shown in red in Figure 19-4, A. The probability of the observed results (9 responses and 11 nonresponses) for a given r is proportional to r9(1-r)11, with the likelihood of r based on the observed results. The prior density is updated by multiplying it by the likelihood. Because the prior density is constant, this multiplication preserves the shape of the likelihood. Thus the posterior density equals just the likelihood itself, shown in green in Figure 19-4, A. The Bayesian analog of the frequentist confidence interval is called a probability interval or a credibility interval. A 95% credibility interval is shown in Figure 19-4, B: r = 26% to 66%. It is similar to but different from the 95% confidence interval discussed earlier: 23% to 64%. Confidence intervals and credibility intervals calculated from flat prior densities tend to be similar, and indeed they agree in most circumstances when the sample size is large. However, their interpretations differ. A credible interval has a particular probability that the parameter lies in the interval. Statements involving probability or chance or likelihood cannot be made for confidence intervals. Any interval is an inadequate summary of a posterior density. For example, although r = 45% and r = 65% are both in the 95% credibility interval in the aforementioned example (Fig. 19-4), the posterior density shows the former to be five times as probable as the latter. A characteristic of the Bayesian approach is the synthesis of evidence. The prior density incorporates what is known about the parameter or parameters in question. For example, suppose another trial is conducted under the same circumstances as the aforementioned example trial, and suppose the second trial yields 15 responses among 40 patients. Figure 19-5 shows the prior density and the likelihoods from the first and second trials. Multiplying likelihood number 1 by the prior density gives the posterior density, as shown in Figure 19-4. This now serves as the prior density for the next trial. Multiplying that density by likelihood number 2 gives the posterior density based on the data from both trials, and is shown in Figure 19-5. The order of observation is not important. Updating first on the basis of the second trial gives the same result. Indeed, multiplying the prior density, likelihood number 1, and likelihood number 2 in Figure 19-5 together gives the posterior density shown in the figure. The calculations of Figure 19-5 assume that r is the same in both trials. This assumption may not be correct. Different trials may well have different response rates, say r1 and r2. In the Bayesian approach, these two parameters have a joint prior density. One way to incorporate into the prior distribution the possibility of correlated r1 and r2 is to use a hierarchical model in which r1 and r2 are regarded to be sampled from a probability density that is unknown, and therefore this density itself has a probability distribution. More generally there may be multiple sources of information that are correlated and multiple parameters that have an unknown probability distribution. A hierarchical model allows for borrowing strength across the various sources depending in part on the similarity of the results.9–9 Randomization was introduced into scientific experimentation by R.A. Fisher in the 1920s and 1930s and applied to clinical trials by A.B. Hill in the 1940s.10 Hill’s goal was to minimize treatment assignment bias, and his approach changed medicine in a fundamentally important way. The RCT is now the gold standard of medical research. A mark of its impact is that the RCT has changed little during the past 65 years, except that RCTs have gotten bigger. Traditional RCTs are simple in design and address a small number of questions, usually only one. However, progress is slow, not because of randomization but because of limitations of traditional RCTs. Trial sample sizes are prespecified. Trial results sometimes make clear that the answer was present well before the results became known. The only adaptations considered in most modern RCTs are interim analyses with the goal of stopping the trial on the basis of early evidence of efficacy or for safety concerns. There are usually few interim analyses, and stopping rules are conservative. As a consequence, few trials stop early. Figure 19-6 shows the sample size distribution for 10,000 trials under the assumption that r = 50%. The estimated type II error rate is 0.1987, which is the proportion of these 10,000 trials that reached n = 20 without ever concluding that the posterior probability of r = 50% is at least 95%. The sample size distribution when r = 20% is not shown but is easy to describe: 9702 of the trials (97.02%) went to the maximum sample size of n = 20 without hitting the posterior probability boundary and the other 3% stopped early (at various values of n
Biostatistics and Bioinformatics in Clinical Trials
Biostatistics Applied to Cancer Research
Clinical Trials
Frequentist Approach
Bayesian Approach
Adaptive Designs of Clinical Trials
![]()
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


Oncohema Key
Fastest Oncology & Hematology Insight Engine